創業型小公司如何做好日常的監控運維
2016-02-20 19:34:20 來源: 呂夢琪 51CTO.com 評論:0 點擊:
從大公司投身到創業型的小公司,我最深的感受就是“由奢入儉難”這五個字。本文是我們在過去的大半年中,在監控報警上做的一些實踐探索,內容包括監控、開源工具的選擇和報警系統設置等內容,供大家參考!

從大公司投身到創業型的小公司,我最深的感受就是“由奢入儉難”這五個字。以前公司里有完善的框架體系,涵蓋了分布式log、監控、實時報警、大數據存儲等等方面,并且有成熟的團隊來運營,使用者大部分時間只要做好集成就行;換到了小公司,初始的一長段時間內,技術團隊只有3人,起步階段一窮二白,而且要做兩個體系的產品,每天業務的壓力就很大,做起事來只能用些比較粗糙的手段。業務的壓力和質量的追求始終是個矛盾。然而,該有的絕不能少,所以我們還是盡量抽出一些時間做好部分必須的框架工作。在我們看來,監控和報警框架是優先級最高的:
1.創業型公司在測試方面,無法做到非常充分,出現問題的概率比較大,需要做好監控。
2.對一個復雜系統的把握,必然是大量的自動化的監控、度量,時刻要知道系統里每個組件的各種運行指標。實際上,有經驗的工程師會體會到,做好監控和運營,在難度和重要性上要遠高于你寫的功能代碼。
3.人少,就要自動化程度高。只有做好監控和自動化報警,才能抽出更多的精力忙業務,晚上才能放心睡覺。
因此,想要做出可靠穩定的產品,首先要有靠譜的監控報警框架去做支撐。而對于像我們這樣的創業公司來說,還需要關心以下幾點:
1.有沒有成熟的開源產品。大公司可以花費一個團隊專心做一件事情;而小公司每個人都是非常珍貴的資源,半個人的開銷都嫌大,所以會更多的借力于開源產品。
2.坑多不多。開源產品的質量和支持沒有辦法和商業產品相比,所以我們需要選用可以hold住的,坑少且穩定的產品使用。
3.能否支持跨語言。我們的產品基本上是C、Java、Python、JSON的混合產品,尤其是后端主要由Java和python組成。
4.可伸縮性是否足夠好。我們的業務和數據在快速發展,所以使用的產品必須能支持后期海量數據的涌入。
5.是否有一定的擴展性。使用過程中必然會有一些特殊的需求,如何快速的做些定制化也是需要考量的點。
6.能否同時支持單機和分布式的部署。我們情況比較特殊,既有傳統的私有化部署的軟件解決方案,又有公有的SaaS以及配套的大規模計算集群。因此,我們很多產品都要有高低配兩種實現,同時通過配置來實現無縫切換。監控系統也不例外。
極度重要,要求又多,資源還少,所以我們在監控和報警方面還是花了一些心思。下面,我會詳細分享下我們所做的實踐探索。
先看監控
首先要談監控。監控的要點就是通過定義多種metrics來輔助我們去了解產品。從硬件到軟件,從LB到后端數據庫的實時運行狀況,幫助我們發現問題、故障甄別和確認恢復。這是最重要的事情。
舉個例子
廢話少敘,先來張以前的圖看個大概:
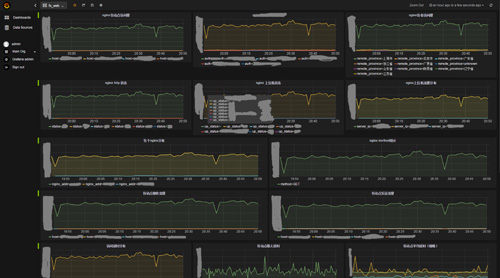
此圖是我們業務系統metrics的一個例子,顯示了我們前置nginx的部分metrics,通過實時的分析nginx log,我們可以得到所有機房nginx在吞吐量、延時、負載分配、流量等等多方面的實時信息,一目了然;還可以根據不同維度進行分析比較,幫我們有效的找到各種異常情況(圖里就有一個小缺口)。類似的metrics,我們目前已經有幾百個,通過不同的面板組織起來,并且還在不斷的增加。目前,公司的原則是每個項目在開發之前,就需要盡可能多的定義出相應的metrics,做好詳盡的監控。
技術選型
眼尖的同學會發現我們用了開源組件grafana。事實上,我們在metrics存儲上采用的就是influxdb/redis+grafana的組合:
1.在我們的SaaS后臺,采用influxdb+grafana 2.0(2.0有單獨的后臺服務)的組合,存儲了海量的metrics,同時滿足大量數據的寫入,以及監控報警系統的頻繁讀取,同時保留橫向擴展的可能性。
2.在我們的測試環境/私有化部署環境,采用redis+grafana 1.9的組合,這個組合部署簡單,開銷相對較小,可以滿足少量的metrics使用。實現上,我們根據influxdb的存儲結構在redis上復刻了一份,并且通過proxy來模擬influxdb的接口。
3.實現方式上,我們提供了Python/Java兩個庫,并通過配置文件來作redis/influxdb的無縫切換。每個應用根據自己的需求來決定配置,并調用api將metrics信息記錄到合適的地方;同時框架自身也做了一些組件專門用來收集系統層面的metrics(比如上面的例子就是通過syslog服務來接受nginx日志,并做實時的metrics統計)。
得出這樣的架構選型,我們當初也是傷透了腦筋:
1.前公司用的是類opentsdb的系統,在使用便捷性和性能上沒的說,但后端強依賴于hbase,對于我們并不合適。
2.當時也看了其他針對這種Time-series data的開源方案,目前其實沒有什么特別好的方案。
3.最終我們還是選了influxdb做為主力,這是一個相對輕量的開源時間序列數據庫,很適合于做為metrics使用:它有類似SQL的查詢語句比較容易上手;自帶簡易管理界面;可以用grafana作為前端看板;還有各個語言的客戶端支持;最后,它最近還是比較火。
4.選redis的原因在于:私有環境下需要一個簡單的方案;比較熟悉,當influxdb碰到問題時,redis版可以作為備胎頂上。
5.最初我們也考慮過用elasticsearch這個大殺器來做metrics使用,然而:
(1)es 是重讀輕寫。由于是搜索引擎的出身,它強調索引。你寫一條記錄,還伴隨著大量的索引工作,有人做過實驗,es和influxdb之間在存儲上是10x的關系。所以es注定寫性能不是強項(就單機而言),而且索引的建立必然帶來延時和復雜性。當然有了索引,在做一些過濾和聚合的時候,搜索引擎的優勢就發揮出來了,能出更多的報表,也能支持長時間的查詢。
(2)influxdb是面向時間序列的數據庫,這一類數據的特征是數據量大,寫入壓力高,所以influxdb在索引上沒有側重,保證了大量數據的快速存儲;缺陷在于,沒有索引,每次查詢需要過濾全量數據,但是基本上能保證讀到最新數據(沒有延遲索引的影響)。所以,influxdb是輕讀重寫。
(3)我們的metrics主要是監控當前狀況,偶爾會回溯一下歷史,同時這些數據會被實時報警系統使用,要求響應比較快。從使用場景和成本的角度,我們最終選擇了influxdb做為metrics的存儲,elasticsearch單做BI工具使用。
metrics監控架構
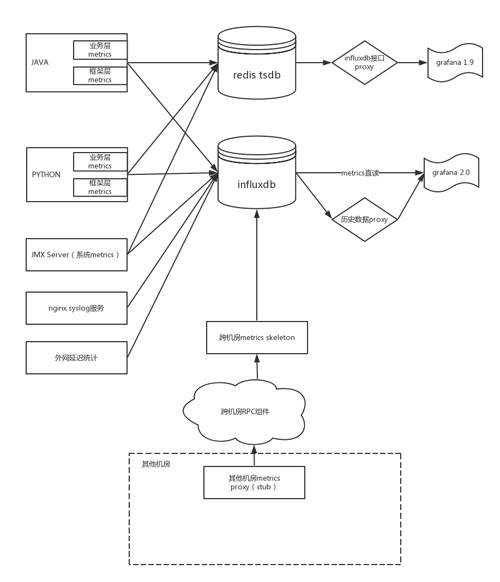
此圖概括描述了我們的監控結構。
1.Python和Java程序通過metrics庫將相應的數據打到指定的地方。
(1)程序里用到的框架組件(如rpc,分布式log等)會由組件自身進行打點,方便框架層面的統一監控排錯。
(2)程序里的業務metrics需要由工程師手動打點,來記錄每個業務和程序模塊的特殊運行狀況。
(3)為了保證后端metrics數據寫入的穩定性,我們在client段做了部分聚合操作,減少打點數據。
‘ * redis和influxdb做成驅動形式,通過配置來指定,開發人員不需要關心具體的實現。
2.通過jmx,我們來獲得系統數據,并打入到metrics系統,來查看各個機器的物理狀況(感謝前同事wxc的jmx庫)。
3.建立syslog服務,對nginx日志進行統計分析,可以得到網站訪問的各種統計信息。
4.對于外網延遲等其他數據,也可以用相應的agent來打入到metrics系統。
5.由于我們的架構是跨數據中心的統一架構,還需要接收各個分機房的數據,我們通過在每個機房建立proxy來接收數據,并由自研的跨數據中心的rpc服務來進行數據傳遞。這樣,在主機房的報表中能看到全國的系統運行狀況。
6.對于線上的大型系統,我們采用grafana 2.0直連來進行數據展示,歷史數據通過proxy來完成。
7.對于私有部署環境和測試環境,我們將數據記入redis版的tsdb,通過proxy來提供influxdb接口,來無縫的接入到grafana 1.9(比較輕量,可以嵌入web應用)之中。
其他監控工具
上文描述的metrics系統解決了我們大部分的問題,是我們監控系統的主要成分。同時,我們還使用了一些其他零散的手段:
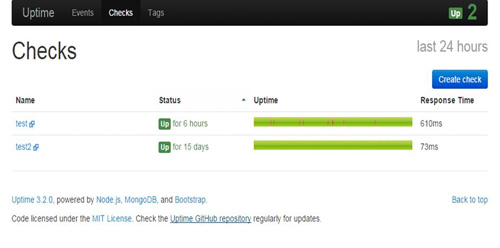
1.uptime。Uptime是一個開源項目,通過獲取網頁的心跳數據來檢測網頁的可用性。如圖:
2.系統資源(CPU、內存、硬盤)監控。系統監控工具很多,一開始我們使用的是collectd這個傳統的工具;后來出于定制化、統一化、練兵的需要,我們改成自己寫Java程序,通過jmx來獲取相關數據,并打入到metrics系。collectd就停止使用了。
3.腳本和外部工具。在遇到特殊需求,通用的系統無法滿足的時候,我們也會通過寫shell腳本來做一些工作,這種方式在開發效率和功能上都比較棒,只是不能很好的和其他數據集成;同時,目前互聯網上也有不少監控服務,我們也用了一些,來作為自身監控系統的補足和備胎。
二次開發
因為主要借助于開源系統,所以有時候需要進行一些二次開發來滿足公司的定制化需求。這里舉一些比較有用的例子:
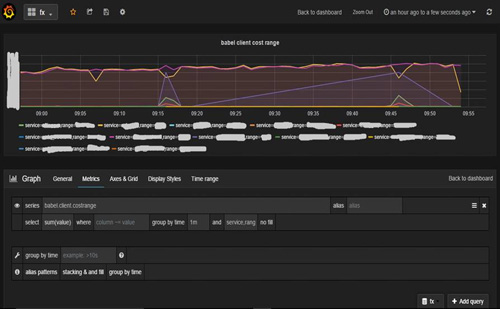
1.grafana默認的分組顯示(group by)只支持一個tag,這種使用場景比較有限。為了讓其能支持多個版本,我們在兩個版本上都修改了它的前端JS代碼,如下圖所示,修改后的版本可以顯示多個tag組合的數據情況(這里是我們的rpc統計中,所有服務的延時范圍統計)。
2.grafana不支持聚合嵌套,所以像distinct count這樣的功能無法實現,這個也通過修改前端代碼解決。

3.grafana可以建多個metrics進行比較查看,但永遠顯示的都是最新的數據,不方便做同環比比較。我們通過proxy來返回一段時間前的數據,來達到這個目的。
4.Uptime檢測https的網頁會有證書錯誤的問題,需要手動在代碼里禁用相應的環境變量。
接著,談報警
光有監控是不夠的,因為這么多的數據和報表,無法通過人肉的方式跟蹤,所以在收集到這么多數據之后,需要有自動化的報警系統來進行進一步的分析和處理。為此,我們基于收集到的海量數據,開發了一個輕量級的報警系統,包括報警系統的完整架構如下圖所示:
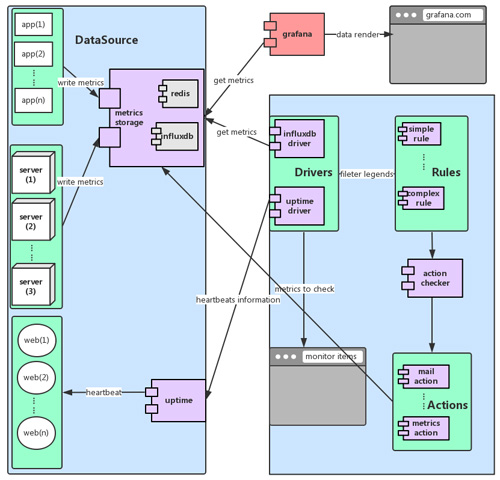
這套系統主要由DataSource,Drivers,Rules,Actions等幾部分組成:
1.DataSource和相應的Driver對應了不同的監控數據來源。
2.rules表示我們的一些報警規則。
3.actions是規則命中后的觸發動作。
DataSource和Driver
data source表示不同的數據來源,每種數據來源都由相應的driver來獲取,并抽象成統一的數據格式(我們采用了類時間序列的格式),這樣可以把數據抽取系統和規則引擎完全解耦,減少開發復雜度。目前,我們的datasource,包括:
1.tsdb中的metrics數據。
2.這是最主要的數據來源,通過獲取存儲在redis/influxdb中的metrics數據,我們可以對海量的監控指標進行詳盡的分析。
3.grafana面板可以生成influxdb dsl,我們的報警系統直接支持利用此DSL進行報警,這樣使用者在grafana面板上配置好監控項后,可以很方便的進行相應的報警。
4.通過上文描述的metrics proxy可以獲取metrics的歷史數據,方便做同環比檢測。
5.uptime的數據。uptime可以對各個url進行監控,通過獲取其數據可以進行網站存活性報警。
6.其他數據。還有其他類型的數據,比如collectd等,也可以方便的集成到報警系統中來。
Rules
從各種data source定期的獲得統一格式的監控數據后,下一步就是通過報警規則進行數據檢查了,來驗證數據是否超出了預設的閥值。報警規則向來是個復雜的問題,需要滿足各種各樣的需求。為此,我們在開發規則引擎時,比較重視減少開發的復雜程度。目前我們的規則,有以下兩類:
1.單數據源簡單規則。簡單規則通過對每次最新的監控數據進行閾值比較,來獲得報警。比如:
(1)上下限閾值比較。這種是最簡單的,定義好上限和下限,就可以發現異常值。
(2)數據存活性比較。當發現某一監控項的數據存在(或消失)時,即報警,用來檢查錯誤指標(或存活指標)。
2.單數據源組合規則。簡單規則產生的報警有可能非常多,我們可以通過對簡單規則產生的結果進行進一步的處理,來減少報警量。比如:
(1)多次報警。當簡單規則觸發的內部報警在一段時間內超過一定的次數時,才進行真正的報警。
(2)報警cooldown。當同一報警不停出現時,此規則會進行相應的抑制。
(3)斷崖式報警。當監控數據出現斷崖式特征時,才進行報警。
3.多數據源組合規則。有時候,單一的數據源還不夠,需要對多個數據源進行計算后獲得。比如:
(1)同環比報警。對同一監控項可以拉取不同時間段的兩條數據,就可以進行相應的報警。
(2)組合運算報警。比如說nginx 2xx狀態比例的監控,可以通過對2xx次數和總訪問次數的計算來獲取。
這里只是舉例描述了一些規則類型,實際系統中會有更多的類型。
Actions
在獲得報警數據后,需要促發一些行為,來完成整個自動化。
1.最常用的報警動作就是發郵件了,通過對每一類報警制定不同的監控人,可以使相關人員第一時間獲悉系統異常。
2.微信報警,郵件的補充。
3.規則引擎產生的數據可以進一步寫回metrics系統,作第二輪的監控報警。比如前文描述的2xx比例(類似的還有各種比例等)。在這種情況下,報警系統相當于一個定時的自動化引擎,來做一些定期的數據處理,方便我們做更好的監控和報表。實際上,這個規則引擎會成為我們后期自動化任務引擎的基礎。
有了這套系統,目前我們的運營監控基本實現了自動化。系統故障時會有相應的報警郵件來通知,這樣開發人員可以集中精力在新功能的研發上。
數字化運營
實際上,整套報警監控系統不但幫助我們去維護網站/系統的穩定性,提高自動化程度,還能提升我們的數字化運營能力,最大限度的提升整個公司的效率。
1.簡單報表。grafana這種可視化工具可以解決大部分初期的報表需求,免掉了初期BI人員的投入。
2.定期報表。我們利用報警系統,做了簡單的修改,可以對一些監控項,在每天凌晨進行強制報警(數據采集選取1天,報警顯示詳細數據),這樣每天早晨都可以收到過去一天的統計報表。由于復用了現有的系統,省掉了相關報表功能的開發。
小結
本文是我們在過去的大半年中,在監控報警上做的一些實踐探索。事實上,在后面的日子里,還需要進行更多、更復雜的工作:
1.接收其他來源的數據,同時大力完善公司內部的監控體系。
2.完善分布式log機制,方便排障和更細粒度的監控。
3.將報警監控系統和生產的業務發布系統打通,來實現彈性擴容和自動容災的可能性。
關于作者

呂夢琪,上海豈安信息科技公司bigsec框架研發負責人,主導底層框架系統和Java服務端的研發工作。她擅長Java研發、分布式系統、監控系統以及各類開源項目的引入和改造。
【編輯推薦】
【責任編輯:武曉燕 TEL:(010)68476606】
上一篇:你一定要知道這個運維產品的能力閉環體系
下一篇:美團如何從0到1構建壓測工具
分享到:
 收藏
收藏
收藏
