PaaS時代來臨,運維人要做哪些準備工作
2016-02-20 19:34:20 來源: 余何 高效運維 評論:0 點擊:
PaaS在業界的標準并未統一,而充分發揮PaaS優勢的很大一部分決定于應用部署架構。如果你有一個時髦的開發團隊,他們遵循去中心化、異步消息通信、無狀態等原則部署應用,那么你可以輕松的將其推送到PaaS。
作者簡介

余何,在運維領域耕耘十余載,07年加入到平安集團旗下的科技公司。2011年,主導集團內最大的應用遷徙與架構變更;2012年開展IT運維管理變革,打通橫向條線,實現技能融合。光陰荏苒,日月如梭,運維往事歷歷在目,流過汗,熬過夜,攤過事,也拿過獎,運維是一個從無到有、日積月累、不斷提升的過程,也是一個需耐得住寂寞,頂得住壓力的行當,在此與正奮斗在運維一線的伙伴們共勉。
“工作不代表你,銀行存款不代表你,你開的車也不代表你,皮夾里的東西不代表你,衣服也不代表你,你只是平凡眾生中的其中一個。”
————電影《搏擊俱樂部》
前言
運維人員在忙碌的工作中要面對各種“新概念”潮汐般地沖擊,他們不得不放下精細化的腳本編程,丟下原生態的性能調優方法,隨大流的淹沒在這瞬息萬變的“新時代”,運維水準的高低與這些新概念也扯上了關系,久而久之我們居然忘了運維的本質是什么。
運維到底需要什么
看看我們每天所做的,都是為了一個共同目標,讓應用快速上線、穩定運行!那些廣告術語:“彈性擴容、自助服務、按需分配”,以及“成本減少多少,效率提升多少”之類的陳詞濫調與你并沒有太多關系,不是嗎?
實際上所有一切都是圍繞著應用開展的,應用自身決定了快速而穩定的80%!面對一個龐大的、遺留的、冗余的、配置雜亂的CRM系統、ERP系統,無論外來新概念如何流弊也解決不了你任何問題,你唯一的出路是好好理解這個系統。
通過一些自動化腳本盡量的減少一些重復性工作,或者你強勢的要求開發人員改造整個系統,采用全新的應用部署架構,但這又是公司層面問題。重要的事情再說一遍,關于自動部署、快速擴容方面,應用自身決定了80%。如果我們還不明白這一點,而迷信于什么互聯網神器,那終將無功而返。
它可以給你什么
在基礎架構引入虛擬化后,關于云的暢想一下子被點燃了,讓我看看下面的圖里:
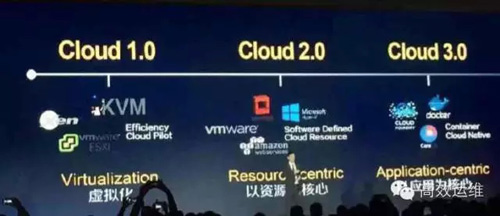
云暢想
姑且讓我們將虛擬化的引入定義為Cloud 1.0,這個時期將物理服務器資源拆解為隔離的虛擬計算單元提供給不同用戶。對于不那么挑剔的用戶,我們完全可以在一臺物理服務器上的OS中提供多個服務給他,這肯定比虛擬化的資源使用率要來得高,但是,我們(運維人員)無法決定與控制應用特性,也就無法避免同一個OS中應用間的干擾,如此一來虛擬化的引入幫助我們解決了大問題。
對于中小企業停留在Cloud 1.0就足矣,而對于大型企業、互聯網企業,他們很快發現其所管理的計算資源陡然上升。亞馬遜Amazon率先將這種虛擬化資源商業化,通過集中管理界面對外兜售,而開源領域Openstack與各虛擬化組件集成,勢必統一行業標準。
無論是公有云還是私有云,在這一輪Cloud 2.0的戰役中,最大的改變是組成了一個更大的虛擬化池,將虛擬機的資源申請、配置管理、服務計費等用另外一種方式加以呈現。而關于虛擬機(OS)之上的東西和以前并無太多差別。是的,亞馬遜Amazon的公有云,他將平時“閑置”的資源兜售給了外部用戶,國內大型“云”提供商,他們很可能是戰略性的“占領”未來行業市場。
至于大多數企業內部的私有Cloud 2.0,則情況又完全是另一番景象。限于這個階段大部分工作是重新梳理了一種配置管理、資產管理以及服務定價的方式,讓我們將Cloud2.0定義為Resource-centric。
事物的發展總是向前的,盡管在發展道路上常會偏離軌道,但總將回歸本位,運維的本質是讓應用快速上線、穩定運行,對于一個應用本身高度可控的企業,它們選擇了更進一步,讓應用適應平臺,在公有、私有IaaS上構建Application-centric的Cloud 3.0,亦即PaaS。

在公有、私有IaaS上構建PaaS
PaaS運維服務的本質
PaaS并不是解決一切問題的靈丹妙藥,它專屬于特定領域,這個領域與應用部署架構、業務場景等緊密相關。如果你發現組織中有大量需要互聯網化的應用場景,它們大部分集中在渠道領域,要求應用加快測試、發布效率,要求隨時進行快速擴容,那么我們可以考慮構建自己的私有PaaS,它可以管理公、私有IaaS資源(虛擬、物理)。
PaaS在業界的標準并未統一,而充分發揮PaaS優勢的很大一部分決定于應用部署架構。如果你有一個時髦的開發團隊,他們遵循去中心化、異步消息通信、無狀態等原則部署應用,那么你可以輕松的將其推送到PaaS。反之,如果有著一大堆跑在Window操作系統上的窗口應用,好吧!PaaS再神奇也于事無補。
至此,讓我們看看在OS之上,運維服務要解決的問題:
1.資源分配
我們大部分時間在進行資源分配,將服務器、存儲、操作系統以及軟件等分配給應用,工作的復雜性圍繞著應用而產生。
2.應用部署
將開發兄弟提供的業務邏輯放到我們所分配的資源中去。
3.服務發現
如果讓用戶找到這個服務,如何讓服務于服務之間可以互訪問。通常的做法有負載均衡、域名解析、配置消息中心等方式解決服務發現問題。
4.監控巡檢
監控巡檢是運維之必須,在此不再累述。
在這里,我們討論前三項,資源分配、應用部署于服務發現。
PaaS平臺功能設計
為了能夠實現PaaS平臺,我們需要保證運維的四個主要工作內容實現自動化,下面這些功能全都是圍繞著實現這個目標而引入的。
1.計算單元打包
虛擬機鏡像、配置管理工具(puppet、saltstack、ansible)所負責的任務就是將應用邏輯計算單元進行打包。計算單元包含了運行業務系統的全棧組件,其涵蓋了操作系統、中間件、依賴包等。
PaaS平臺中,我們選擇Docker替換原有的方式,作為一個輕量級容器,它比虛擬機更加節約資源,同時可以基于一份軟件介質運行多個實例,Docker的倉庫、鏡像與容器三元素讓應用邏輯計算單元大大得到了簡化。
誠然,ansible這類軟件配置工具已經非常輕巧、快捷,并且滿足95%以上的需求,但當決定將PaaS構建在跨IDC、跨第三方數據中心時,基于鏡像的分發能夠更加穩定的滿足我們需求。Docker也有其缺點,例如不支持32位平臺,不支持windows服務器。

Docker+Ansible 完成計算單元打包
2.資源動態分配
與Cloud 2.0的IaaS不同,用戶并不關注如何獲得CPU、內存、存儲資源。他們僅關注自身應用計算邏輯的運行,他們希望資源是動態分配、彈性擴容的。
數據中心需要一個統一的資源管理者,它將所有資源(無論虛擬、物理)抽象成一個整體,如同一個數據中心操作系統。這種資源的抽象不僅僅要滿足服務型計算,還要滿足大數據時代的MapReduce計算,以及今后的各種類型計算,這意味著資源分配與任務調度兩部分功能是解耦的。
在分布式資源管理領域,主流的選擇是Mesos、YARN。
◆ Mesos:Mesos最早由美國加州大學伯克利分校AMPLab實驗室開發,后在Twitter、Apple、Netflix等互聯網企業廣泛使用,成熟度高。
◆ YARN:Apache Hadoop YARN是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統,可為上層應用提供統一的資源管理和調度。
其他的選擇還有Kubernetes、CloudFoundry、OpenShift等方案,但這幾種不滿足資源分配與任務調度解耦,對應用規則要求太高,并不容易兼容現有應用。在我們環境選擇了Mesos,其獨有的靈活性保證了支持更多類型的上層分布式計算應用。

Mesos 分布式資源管理
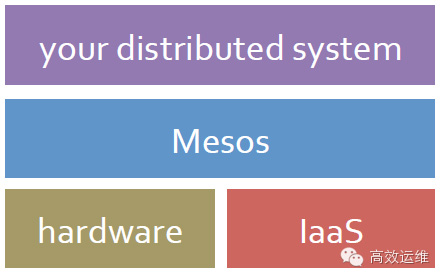
數據中心OS
3.任務調度功能
任務調度器與資源管理器的最大不同在于其要對運行中的應用服務負責,包括啟動、停止服務,監控服務以及在服務失效時的故障轉移。最初的分布式架構設計中,人們常常模糊了作業調度與資源管理二者間的界線。
其一是分布式平臺是為某一專屬計算類型服務,例如Hadoop平臺為MapReduce計算類型服務。
其二,作業調度與資源管理的交互頻度高,合二為一后的效率更高。但隨后人們發現資源管理器的功能是相對穩定的,而作業調度因為計算類型多。
并行計算有MapReduce、Stream,普通計算有Service、批處理等,每一種計算類型的作業調度方式完全不同,如果將資源管理器與作業調度器綁定在一起則會失去分布式平臺的計算靈活性。
是以Mesos為核心,支持多領域的分布式集群調度框架,包括Docker容器集群調度框架Marathon、分布式 Cron(周期性執行任務)集群調度框架Chronos和大數據的主流平臺Hadoop和Spark的集群調度框架等,實現系統的資源彈性調度。
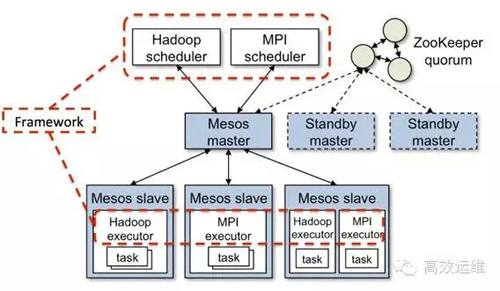
Mesos架構示意圖
對于服務型的長任務,我們選擇Marathon作為其任務調度器。
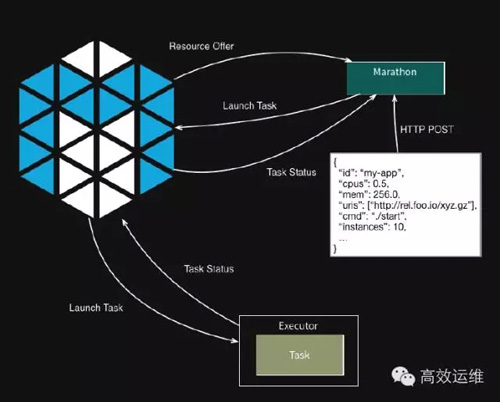
Marathon任務調度
4.服務發現功能
服務發現有兩種形態,一種是用戶(人)來訪問的,一種是應用之間互調的,對于前者需要保持一個穩定的入口(不變),而對于后者,如果在一個寬松的環境里,是運行變化,并接受變化通知的。而對于長服務型計算類型,除了解決服務發現外,還要考慮將任務分發到多個節點,亦即負載均衡問題。
服務發現上可選的有通過動態寫入DNS系統來滿足用戶需求,通過zookeeper之類的分布式協調系統充當配置中心通知外部系統。而在負載均衡上,企業級的專用設備,例如F5等都提供了API接口以供調用,而開源軟件上通常采用Haproxy。
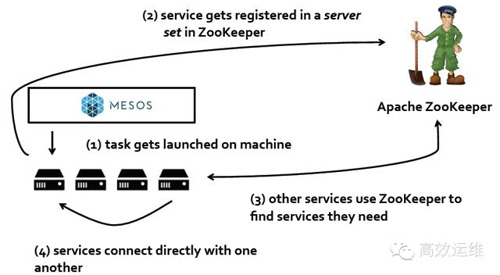
通過zookeeper實現服務發現
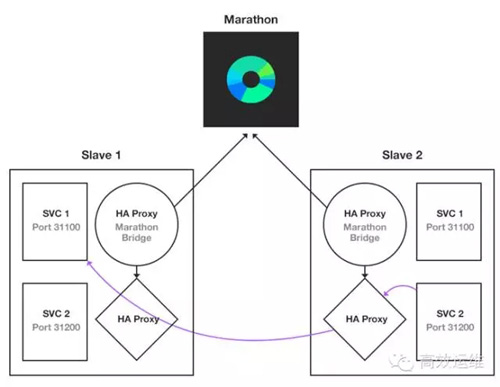
Marathon的Haproxy服務發現方案
5.日志集中管理
在一般情況下,日志以文件的形式存放在本地操作系統上以供查詢,而在分布式系統中,計算單元不會再固定于一個物理節點上。如果日志仍以文件形式存放在本地,隨著計算單元的漂移,日志將留存在與計算單元沒有關系的物理節點上。對于系統管理人員、運營人員來說,日志查詢檢索將變成一門繁雜工作。
在分布式平臺上構建集中的日志管理平臺,將各種類型的日志收集、索引好,以消息的形式看待每一條日志將成為分布式平臺上的一個重要功能。采用開源社區流行的ELK組件(elasticsearch、logstash、kibana),我們會看到如何將所有節點的日志導入到一個集中平臺進行可視化管理。

elastic日志集中管理
PaaS下的運維發展之路
PaaS時代的來臨,對運維職業發展將產生深遠影響,一個嚴重的誤區是認為云計算將徹底取代運維行業,實際上在IT發展的過程中,對運維的要求在不斷提高。云計算、大數據、物聯網以及移動互聯等無一不是這個時代向前發展的標志, 只要IT越貼近用戶,就會產生更多的數據、發現更多的需求,運維則愈加之重要。
運維職業發展的三個硬道理是:
1.不變應萬變
要做到不變應萬變,就必須掌握業內最基礎、最穩固的知識點,打下結實的基礎。相對于開發應用框架、前端UI的變化,存儲、計算、網絡三大資源知識是非常穩固的,即便是變化也一定是建立在基礎原理之上。
互聯網變化之快,新技術層出不盡,運維人員不能太過于跟風,一定要看清事物背后的本質,與基礎原理相聯系,深入底層內部思考,這樣才能做到萬變不離其宗。以Linux操作系統為例,運維人員并不需要將所有發行版的安裝、命令等背誦入流,而是精通一到兩種,并通過操作系統的運行原理來解釋一切問題。
2.精通編程
不會編程的運維人員不是好運維,在開源風潮涌現的年代,可以預見未來對運維人員的開發能力要求會非常之高。系統開發與應用開發在完全不同的兩個維度,系統開發更貼近于底層,掌握程序的運行原理對編程能力的提升有極大幫助,例如可執行文件的結構、在內存中的形態等。
運維人必須精通一門編程語言,參與到社區,品讀開源代碼,養成編程習慣。引用Linux之父Torvalds的一句話“just for fun” ,這是運維人看待編程應保持的心態。
3.敏銳觀察力
時代依然在不斷變化,運維人雖不必立即掌握每一項新出爐的技術,但他們必須保持對行業的關注度。預留一些時間給自己閱覽社區新聞,積極參加線下社區活動,隨著新技術的成熟以及自己的個人興趣,在新興領域投入必要的時間。
Larry Wall是Perl語言的設計者,他屬于運維鼻祖,也就是系統管理員。當時Larry遇到了一個問題,如同我們現在遇到的一樣。他需要在繁雜的內容中萃取文本信息,而手頭的工具只有awk和shell這些工具可以幫助解決問題。
這些工具用起來卻是那么痛苦,Larry太懶了——如果用awk來做的話,要做大量工作,這讓他無法忍受;Larry也太急躁——awk做起來很慢,他可等不及;最終他的高傲促使他完成了一件壯舉,設計一門新語言——Perl,造福整個社區。是的,你會發現運維時代在變,但同樣的故事還在發生,你是否已做好準備?
【編輯推薦】
【責任編輯:武曉燕 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
