運維改革探索(一):用多層級監控實現可視化運維
2016-11-15 12:57:00 來源:來源:DBAplus社群 評論:0 點擊:
當前運營商業務支撐系統正向云化發展,以某移動公司為例,近年先后進行了經分系統云化、大數據系統建設、BOSS云化,現正在進行CRM云化,同時構建企業級資源池。
作者介紹
朱祥磊,山東移動BOSS系統架構師,負責業務支撐系統架構規劃和建設。獲國家級創新獎1項、通信行業級科技進步獎2項、移動集團級業務服務創新獎3項,申請發明專利13項。
一、背景
當前運營商業務支撐系統正向云化發展,以某移動公司為例,近年先后進行了經分系統云化、大數據系統建設、BOSS云化,現正在進行CRM云化,同時構建企業級資源池。經過幾年的探索,深刻感受到云化給業務支撐系統帶來高效低成本的優點,但同時也對運維能力帶來了更高的要求,針對傳統架構下的運維管理模式已經越來越不適合云化下的要求,主要表現在:
1)監控問題:所管理的機器和進程數量越來越多,呈現幾十倍增長,傳統運維由于機器數量小,監控都是基于點的,但是云化后,點變為一個個集群,且集群內機器數量龐大,基于點的監控方式越來越難以滿足大量機器運維管理需要。
2)工具問題:隨著機器數量增加,基于腳本或基于傳統的發布變更工具難以適應集群內大量機器運維的需要,無論在自動化程度、效率、靈活性、便捷性、安全管控等方面均存在問題,迫切需要改變,引入新的工具。
3)分析問題:數據助力運維,但是由于云化后,針對運維的有價值數據或日志分散在大量的機器集群上,難以像傳統架構一樣實現集中化分析和呈現,需要研究解決在分布式云化架構下的運維數據集中分析問題。
4)服務問題:“IT即服務”,隨著云化的演進,對敏捷運維能力也提出了更高的要求,現有ITIL基于流程、按照不同專業展開的運維服務模式,難以適應云化資源池所需的跨專業運維模式,需要改變。
二、解決方案
為應對云化后運維模式帶來的挑戰,我們進行了積極的探索,參考互聯網企業做法,引入相關開源和商用軟件以及互聯網企業的運維理念,結合運營商實際,初步構建了一套面向云化架構的可視化運維體系,并初步進行了落地運行,取得了較好的效果。
整體架構圖如下:
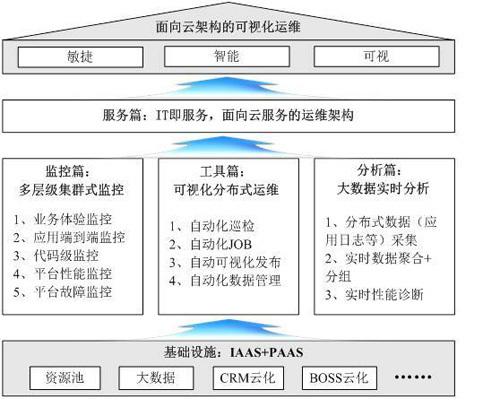
下面將一一展開論述。
三、監控篇:實現多層級集群式業務監控
可視化運維的核心要點之一是要解決可視化業務監控度量的問題,我們經過近幾年對云架構下各種監控手段和措施持續不斷的摸索、改造、優化和完善,逐漸建成一套基于平臺故障監控,平臺性能監控,應用代碼級診斷,應用端到端和業務體驗監控于一體的多層級集群式監控系統,如下圖:
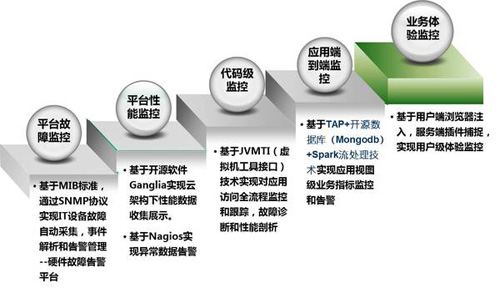
第一級:業務體驗監控。是直接面向一線用戶感知的體驗監控,通過對用戶終端到服務端整條鏈路各個關鍵環節性能指標(如網絡時延等)和各類錯誤進行全流程跟蹤、監控,及時發現用戶感知相關的各類問題。
第二級:應用端到端監控。通過構建業務支撐系統自身整體架構視圖,并對每個節點部署監控元素,利用聚合、分組機制,能直接發現系統各個環節各個渠道的問題,便于快速定位問題和影響面,能支持上千臺機器的集群規模。
第三級:應用代碼級診斷定位。在發現應用性能、故障需要進一步深入定位時,可通過代碼級診斷定位手段實現代碼跟蹤,快速確定真正問題點。
第四級:分布式平臺性能監控。針對成千上萬臺機器集群規模的平臺性能實現快速部署,實時監控手段,針對集群內平臺性能相關的各個指標實現直觀的判斷和監控。
第五級:云平臺故障監控。針對成千上萬臺基礎設備,如小型機、x86、虛擬機等,構建統一的云監控平臺,實現系統故障級別的管控。
通過構建上述五級監控,基本全涵蓋了從“一線用戶感知到后端運維”,從“應用整體視圖到程序代碼內部”,從“平臺故障監控到平臺性能監控”,各個維度的監控。
第一級:業務體驗監控
目前支持業務體驗監控的方式有很多,如鏡像方式、代理方式、插件方式等,我們經過測試驗證,最終選擇用戶端瀏覽器注入、服務端插件捕捉方式實現云化后的用戶體驗監控。相較其他方式,數據無丟失,度量更加真實可靠。
1、主要做法
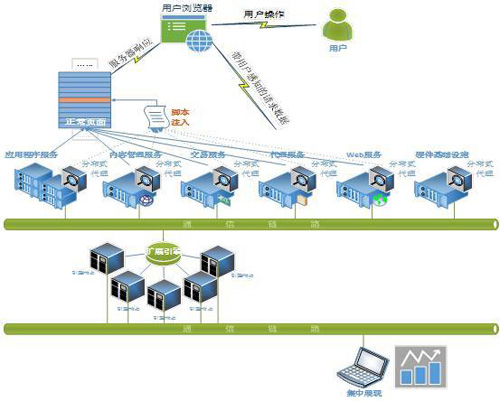
上圖是整體架構圖,分布式代理負責向用戶瀏覽器下發監控插件、收集用戶感知數據;擴展引擎負責對用戶感知數據處理和分析,最后在控制臺集中展現。
以實體廳為例,監控組網和實現原理如下圖所示。在Web服務器或應用程序服務器中啟動用戶體驗功能,會改變服務器向用戶返回的具體內容,主要包括在響應用戶的頁面頭部增加了瀏覽器插件腳本的引用路徑,便于用戶在訪問任何頁面時均會加載瀏覽器插件,這個過程稱為瀏覽器注入。該插件的主要作用是:捕捉用戶行為及與服務器的關聯關系、用戶行為的響應時間及可以量化的性能指標(Apdex)。
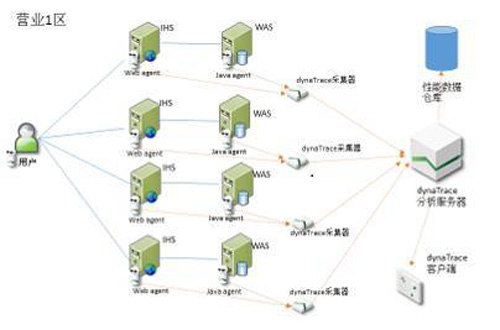
瀏覽器插件實現了對頁面元素事件處理過程的抽象,首先,通過jQuery捕捉界面元素的單擊、滾動及鍵盤敲擊等具體行為,及該行為對應的服務器請求;其次,對每一次用戶操作,插件會記錄用戶真實的響應時間,響應時間再進一步細分為客戶端時間、網絡時間和服務器處理時間等。與網絡流量解碼不同的是,代理方式無法獲取數據包在網絡上傳輸的精確時間,而只能通過帶寬的實際評估計算出來,實現原理是:每5~10分鐘會從用戶瀏覽器自動發送1~10k大小不等的文件給服務端,根據響應時間評估帶寬大小,再按照實際頁面大小估算網絡時間。
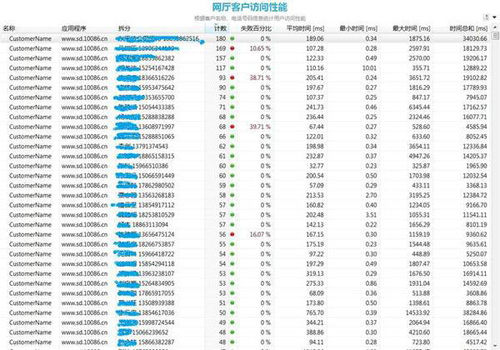
用戶體驗監控界面如下,以用戶訪問作為最小統計單位,得出用戶每一次訪問的感知情況,是滿意、可容忍還是失望。對于每一次失望的訪問可以呈現出具體原因,失望是因為哪一步操作而失望的。
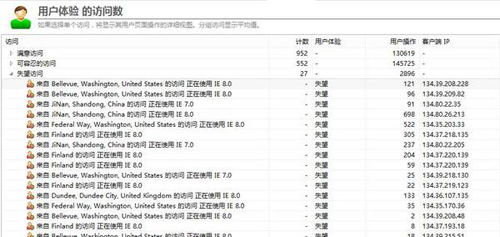
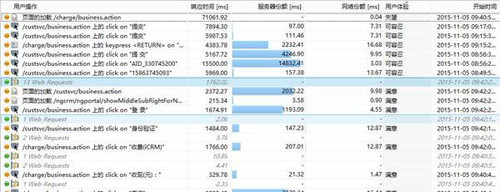
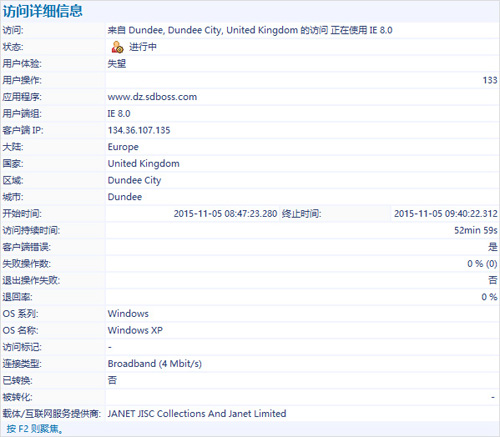
在找到引起用戶失望的操作后,可以分析導致操作失望的原因,是網絡份額還是服務器份額。對于用戶感知較差的訪問,可以通過帶寬評估出用戶可能的帶寬大小,如下圖:
2、效果舉例
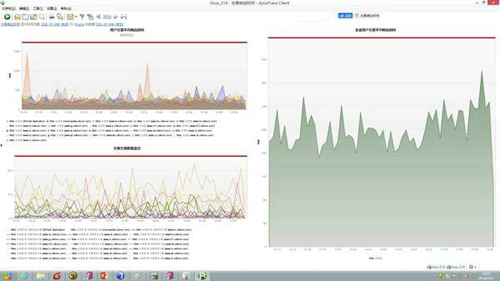
1)建立直觀的用戶感知評價體系。在用戶感知評價體系中,響應速度最為關鍵,基于用戶體驗的監控為評價體系提供了有效數據,如業務辦理操作復雜度、交互速度、業務辦理成功率和轉化率等,如下圖所示,某時段內業務的體驗詳細情況:
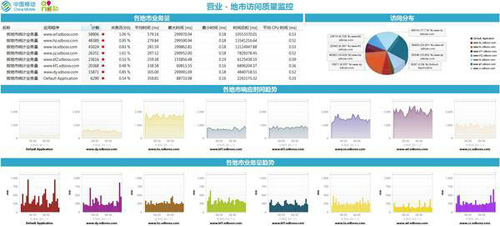
2)實現用戶訪問性能和地市服務質量的監控:
第二級:應用端到端監控
用戶體驗偏重用戶行為和相關業務的監控,為深入了解云化架構下的應用各個環節的運行情況,提升維護工作效率,還需要構建一套面向全業務、全渠道、端到端的業務監控系統,用于整體業務監控視圖,實現領導視圖和運維視圖合一的架構。
我們通過引入TAP+開源數據庫(Mongodb)+Spark流處理技術,對云服務器上網絡流量進行實時動態采集,根據代碼規范和業務規則對數據進行過濾、排重,解碼,分析、計算和交易關聯,最終實現基于業務整體視圖級動態監控,為后端運維提供了快速、高效支撐。整體架構如下:
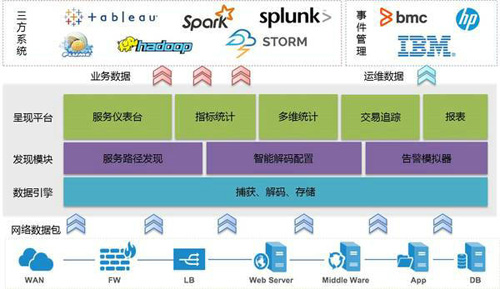
1、基本原理和實現過程:
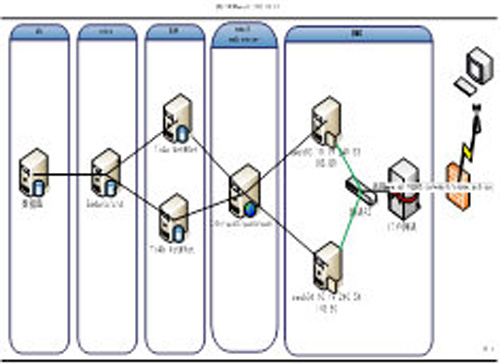
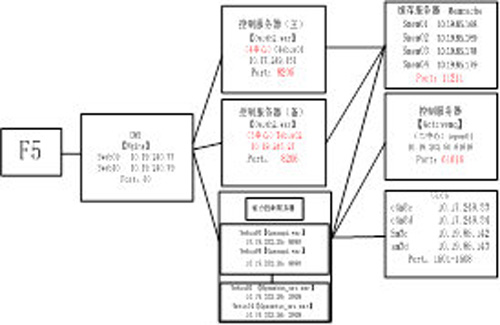
1)業務配置:從業務渠道維度出發,根據業務訪問關系,梳理出系統部署圖和業務關系視圖,包括系統內部相互之間訪問關系、訪問端口,組件屬性,協議解碼等,如下面是能力開放平臺系統部署和應用訪問視圖:
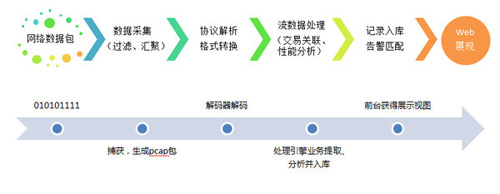
2)數據采集和流處理:首先、系統通過自動部署探針捕獲所有監控云服務器端原始數據后進行初次過濾后統一匯聚到TAP交換中心,流處理中心會根據每個業務組件探針從TAP交換中心捕獲數據并轉換為原始數據包。其次、解碼器根據TCP會話標識(flowid)將不同組件的原始數據包關聯成一個完整的會話流,并根據編碼規范對關聯后數據包進行協議解碼生成原始交易記錄;最后、處理引擎根據已配置的業務規則對原始交易記錄進行業務信息(如類型、渠道等關鍵字)提取、分析生成業務指標記錄并將結果傳給負責web展現引擎后入庫。
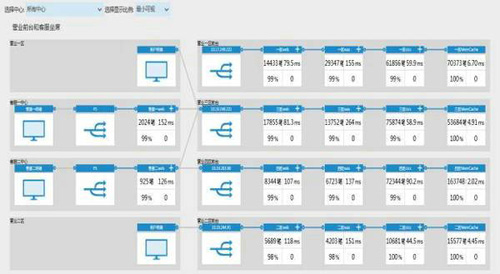
3)動態監控:負責指標展現引擎(exporter)獲取到數據后,將結果實時更新到前臺web相應組件,目前我們已經實現實現對NGCRM、客服,網廳、商城,短廳,一級BOSS,渠道便利店,終端管理平臺,移動工作臺,自助終端和能力開放平臺等關鍵業務渠道應用級監控:
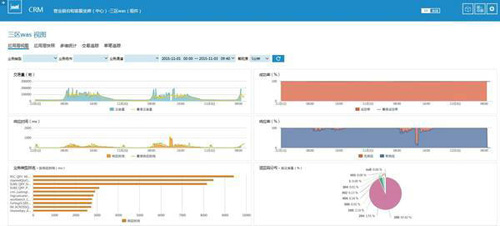
4)指標統計:告警模塊(alerter)輪詢數據庫中記錄根據業務配置基線和閥值生成趨勢報告和告警信息。
2、主要特點
1)靈活、高效快速部署
應用視圖級監控以網絡數據為依托,能夠自動發現應用組件之間連接性和訪問關系(如IP地址,服務端口,應用協議等),非常適合云架構下的敏捷業務監控部署,整體步驟只需3步:
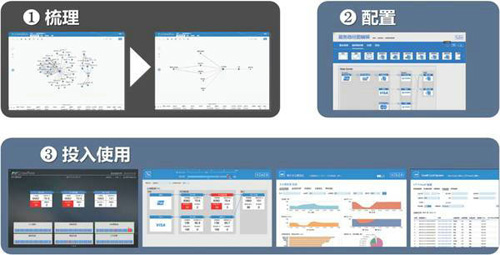
2)可視化運維,快速定位
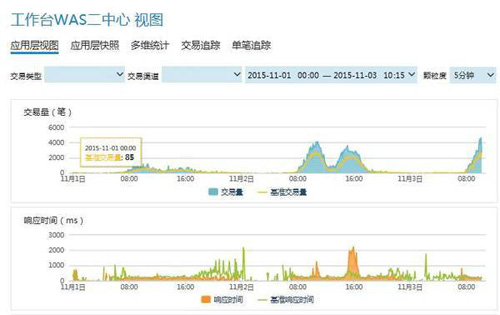
基于動態運行視圖可以實時捕捉并跟蹤所有組件指標波動(如業務量、成功率、響應時長等指標)和基線告警,相比傳統拉網式逐個排查方式,運維人員能夠快速、準確定位故障,數據指標還可以應用于服務質量評測和變化趨勢分析。
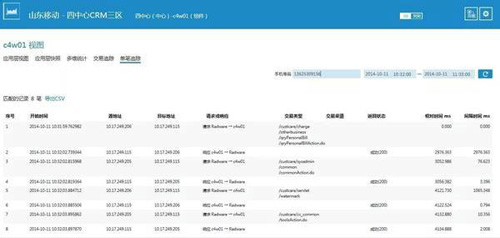
3)自動關聯,端到端跟蹤
通過不同應用組件間交易自動關聯,可以跟蹤深入到業務系統內部,詳細分析業務內部各應用之間交互運行軌跡和交互關系,實現問題回溯和快速定位,可基于手機號等業務關鍵字做深入挖掘分析:
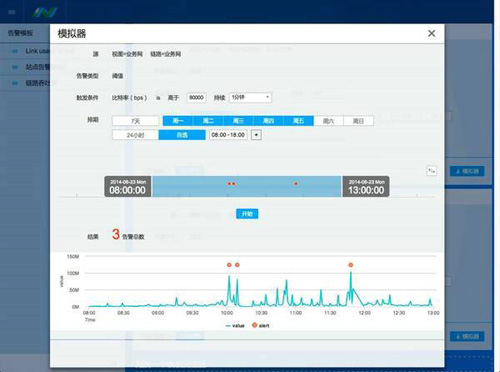
4)智能模擬告警,告警更準確
提供模擬器功能,可自動調整告警閾值,和歷史上發生問題的情況對比,最終得到比較合理的告警閾值。
第三級:代碼級問題診斷
無論是業務體驗監控,還是應用端到端監控,都是粗粒度監控,在很多情況下,如出現應用性能等,盡管能及時發現問題,但是如何解決定位,還需要更加細粒度的診斷手段。為此,我們引入基于代碼級的業務監控手段,用于解決應用云化后復雜的環境下的問題定位診斷場景。
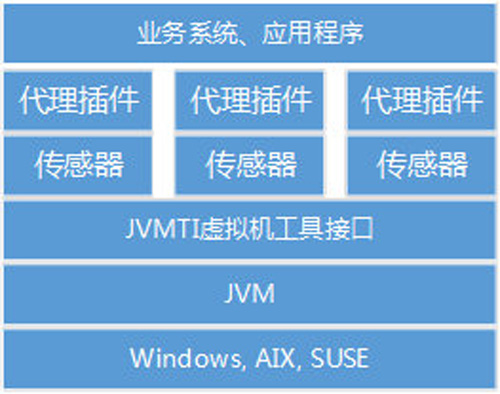
1、整體架構
代碼級監控系統基于JVMTI(虛擬機工具接口)技術實現,整體架構如下圖所示,JVM是目前為止使用最多的跨平臺運行環境,在此基礎上構建JVMTI接口具有較好的底層植入能力,針對不同業務將JVMTI的接口封裝成傳感器,并由代理插件調用來捕獲代碼級數據。
2、用于故障診斷及性能剖析
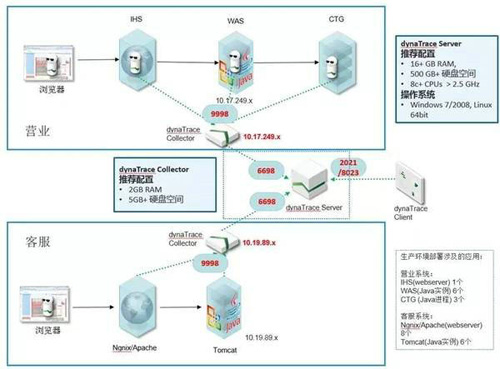
基于JVMTI的監控工具可以追蹤和監控任何一筆用戶請求在服務器端的代碼軌跡,通過對比堆棧上各層函數耗時,可以迅速找出執行熱點,并定位到性能問題的根因。同時,對調用的函數啟用出入參數捕獲,可以詳細了解業務執行時的快照,幫助定位業務層面的問題。下圖為我們JVMTI代理插件部署邏輯圖。
應用場景舉例一:
在6月份通過代碼級監控定位到智能營銷平臺性能問題,通過便利店調用營銷平臺交易通常在1~2分鐘時間,消耗服務器大量線程池資源,同時在營業系統調用便利店過程中,采用了同步阻塞式調用,多次對用戶體驗造成影響。CPU采樣分析發現91.6%的性能損耗發生在應用服務器層,進一步深入到最底層調用找到程序試圖對一個超大的ArrayList進行遍歷導致執行效率低下,解決方案是:采用更高效的哈希集合取代ArrayList,如下圖:

應用場景舉例二:
通過代碼級監控發現低版本的log4j組件引發的線程死鎖,導致青島自助終端短時間無法登錄,如下圖:

第四級:集群式平臺性能監控
除了上述業務和應用監控手段外,為了對各集群中成百上千臺機器和分區進行直觀高效的集中監控并告警,我們引入開源軟件Ganglia和Nagios并進行定制,構建了一套適合云化的集群式平臺性能監控系統。目前已經實現了對大數據集群、BDS集群、CRM共約520個節點的集中監控和告警,內容包括節點和服務狀態、資源利用率、網絡、IO流量等指標,以及Hadoop和HBase的各項性能指標。通過個性化定制,還可以方便地增加其他需要關注的指標項。
1、云化平臺性能監控系統的優勢
相比傳統的網管監控,以及其他諸如nmon等性能監控手段,我們構建的分布式云平臺性能監控系統具有以下幾大優勢:
圖形化web界面,通過曲線對整個集群中設備的各項性能指標進行直觀的展示,便于分析問題,發現性能瓶頸。而不是單點的展示。
層次結構清晰,通過定義對節點和服務分組、分類,逐級檢查,適合大規模服務器集群。
存儲性能指標數據,方便統計分析、生成和導出報表。
擴展性強,支持多種開發語言(shell、C++、Perl、Python、PHP等),用戶可以方便的根據需要定制監控項目。
2、性能監控系統架構
我們構建的云化平臺性能監控系統采用開源軟件Ganglia(版本3.7.1-2)和Nagios(版本4.1.1)。前者主要負責收集、展示性能指標數據,后者則側重于告警機制。
1)Ganglia系統架構
ganglia主要有三個模塊,如下圖所示。
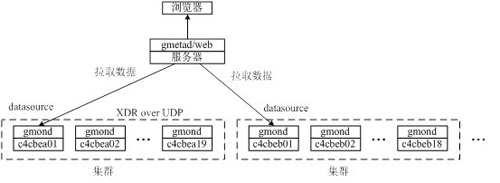
gmond:部署在各個被監控節點上,定期收集節點數據,并進行廣播或單播;
gmetad:部署在服務器端,定時從data_source中拉取gmond收集的數據。在每個集群中選擇一個節點定義為data_source;
ganglia-web:部署在服務器端,將監控數據投遞到web頁面。
2)Nagios系統架構
Nagios主要包括nagios daemon、插件(plugins)和NRPE模塊,如下圖所示。
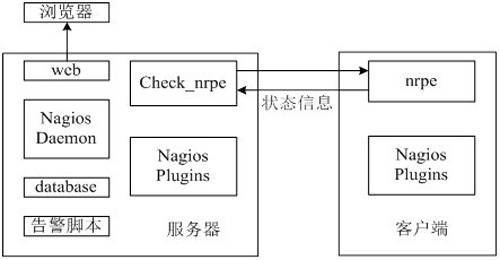
Nagios按照設置的周期調用插件來檢查監控對象狀態。執行check_nrpe,并指定參數(檢查命令,比如check_disk),告訴遠端被監控節點的NRPE daemon需要檢查哪些指標。NRPE 運行本地的各種插件進行檢測,然后把檢測的結果返回給check_nrpe。服務器端維持一個隊列,所有返回的狀態信息都進入隊列。共有4種狀態信息,即 0(OK)表示狀態正常/綠色、1(WARNING)表示出現警告/黃色、2(CRITICAL)表示嚴重錯誤/紅色、3(UNKNOWN)表示未知錯誤/深黃色。Nagios根據插件返回來的值,判斷監控對象的狀態,并通過web展示。同時調用告警腳本smswarn,發送告警短信,同時,也可以配置郵件告警通知。
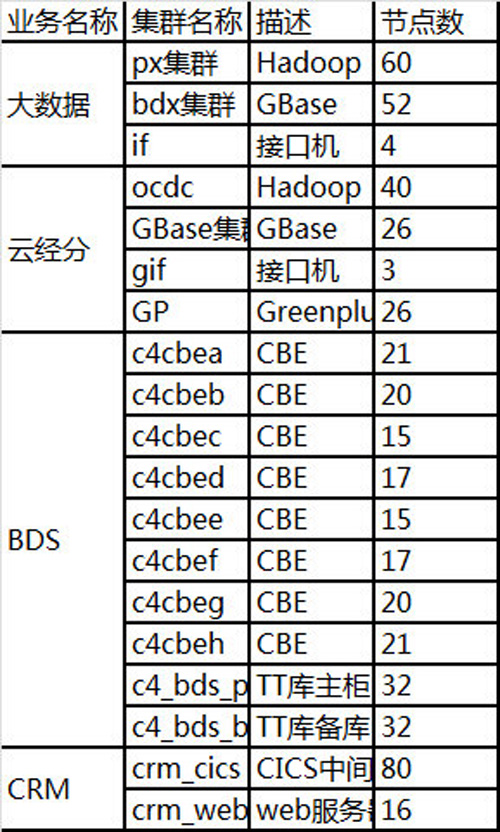
3)已實現的被監控節點列表
目前云化平臺性能監控系統共監控如下節點,分為19個集群:
3、云化平臺性能監控效果
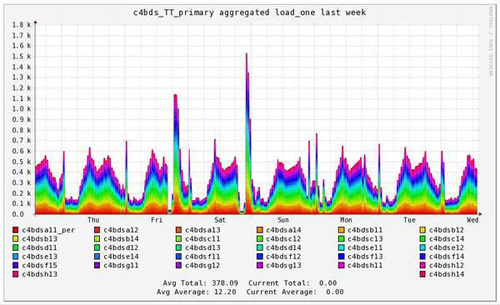
1)Ganglia效果示例
通過建立基于Ganglia的性能監控平臺,改變了對平臺性能監控的認識,大大提升了監控水平。
如下:一個界面內可以實現整個集群的運行趨勢概況:
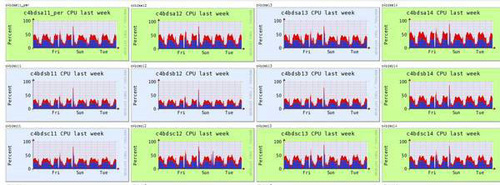
下面是云集群內每個機器的運行情況,超過幾十種指標可選:
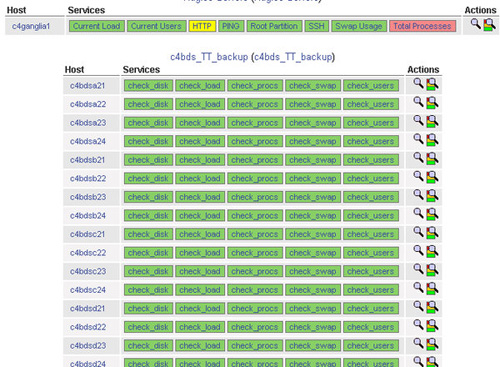
2)Nagios效果示例
第五級:平臺故障監控
解決了業務和平臺性能的監控問題,還有硬件和OS層面的監控問題需要解決,由于云化的不斷深入發展,各類設備很多,各種設備特別x86快速增長,傳統監控方式、機房巡檢等方式維護難度越來越大,已無法滿足工作要求,為解決該問題,我們新建一套基于硬件和OS層故障的云監控告警平臺,該告警平臺基于國際MIB標準,通過SNMP協議方式實現海量設備故障數據自動采集,事件解析、分析,最終通過和BOMC融合實現業務信息關聯和告警展現。
下圖是硬件告警平臺部署架構圖,最底層是包含各類被監控對象,包含各類設備的硬件層面,第二層是硬件mib層,采用分布式架構,利用分布式采集、分布式snmp協議等技術實現海量硬件設備的告警數據采集,第三層為故障解析和分析層,利用國際標準MIB進行故障解析、分析流程標準化,最上一層為展示層。
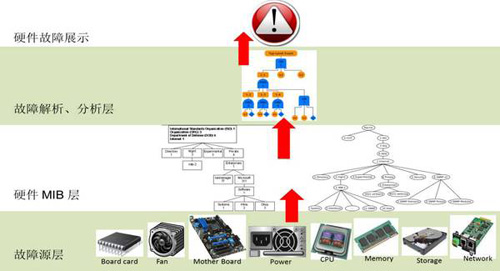
具體部署架構如下:
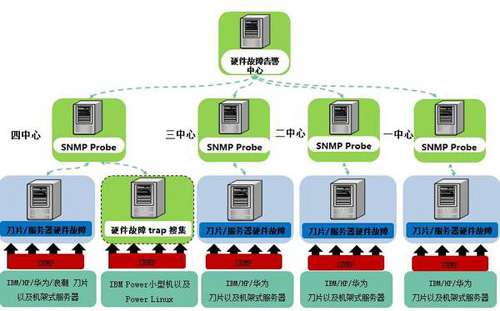
下面是幾個展示實例:
集中的故障展示:
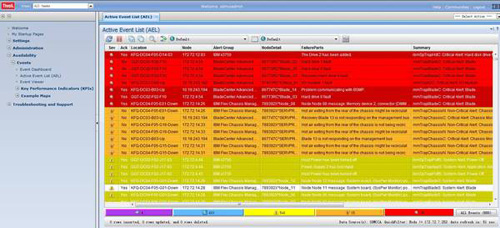
OS和虛擬機層面詳細展示:
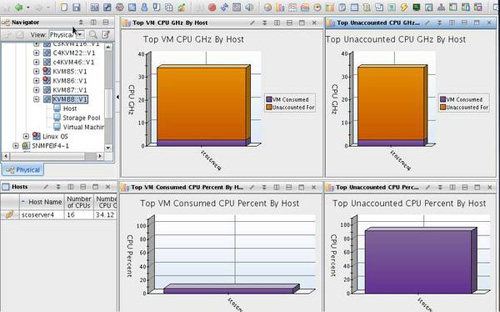
hypervisor層存儲池監控:
【編輯推薦】
【責任編輯:武曉燕 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
