運維自動化重點解讀之監控系統(三):架構(1)
2016-02-20 19:33:33 來源: Reboot運維開發 51CTO博客 評論:0 點擊:
架構這個詞太大了,這里我們縮小一下,只來談談宏觀的監控系統整體架構。在這個范圍里面,web由于負責統一的系統管理和操作功能,縮減為一個模塊。監控系統第一層的架構最粗粒度的幾個模塊就是這三個:web、數據采集、數據處理。

這一篇我們來聊聊監控系統的架構。歡迎大家加入運維開發討論交流群來交流,群號 365534424,本文僅授權51reboot、51cto上發布。
架構這個詞太大了,這里我們縮小一下,只來談談宏觀的監控系統整體架構。在這個范圍里面,web由于負責統一的系統管理和操作功能,縮減為一個模塊。
最簡單的架構如下圖:
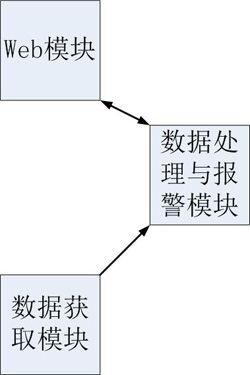
這是監控系統第一層的架構。比照百度地圖的話,我們可以認為這個是全國地圖。最粗粒度的幾個模塊就是這三個:web、數據采集、數據處理。
PUSH和PULL
我們先來關注數據采集模塊到數據處理和報警模塊的這個環節。
推和拉,技術選型里面常常遇到的一個選擇題。 在Client/server結構中,信息獲取方式是按“拉”(Pull)的模型進行的:服務器根據用戶終端發送的服務請求進行處理并返回用戶所需的結果。在Push模型中,服務器把信息“推”給Client。雖然兩者數據傳輸的方向都是從服務器流向Client,但操作的發起者是不同的。從“信源”與 “用戶”的關系來看,信息的流動可分為兩種模式,即信息推送與信息拉取模式。
兩種模型的對比見表格:
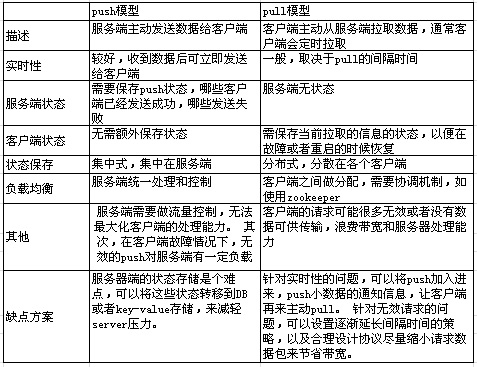
其中PUSH的好處是及時性好。但缺點是服務端要有比較復雜的狀態管理。同時在到達率等方面都會有一些糾結的地方。而PULL的好處則是服務端簡單,狀態管理簡單,但缺點是時效性上不可控。體現在監控系統上,如果所有要監控的監控項,都是需要Server端PUSH給Client,假設Client所在服務器關機了,那PUSH的時候就是不可達的。Server端就得想辦法記錄下來,并且再做重試等失敗處理。而如果是Client端主動來PULL就好辦了,服務器開機啟動之后,Client立刻來拉取。到達率肯定要好,對Server的管理也簡化了。但缺點就是想生效一個監控項,只能等著Client來 PULL,而無法立即生效。
這里還有一個比較經典的例子,也是我面試別人的時候總喜歡問的一個問題。當然我問面試者的時候主要是想去看看TA的邏輯思維能力。
題目:微博大家都用過。里面你可以關注一個人,也可以被人關注。當你發一條微博時,關注你的人都會收到一條提示。當你關注的人發一條微博時,你會收到一條提示。 請問這個提示,是PUSH 還是 PULL到你的微博客戶端(瀏覽器或者手機微博)上的?
面試者:肯定會有人說,PUSH唄。
面試官:OK,然后我就會問了,姚晨在新浪微博上的粉絲數是5000多萬,她發一條微博,是不是得PUSH 5000多萬個消息到各個賬號去?
面試者:額,那就是定時PULL
面試官:確定嗎?幾千萬個客戶端都PULL?
面試者:額。。。 面試者開始額頭黑線了。
面試官:請問該怎么辦?
PUSH的話,姚晨的一條微博,在系統里面就要產生5000萬條消息要處理。如果她一天發個100條,估計新浪微博瘋了。這還沒有考慮很多客戶端不登陸,消息就得緩存著。還有很多客戶端一下子通知不到,還得處理失敗。
PULL的話,如果大量用戶在使用的生產系統,對存儲和緩存是一個很大的挑戰。
具體的,大家可以再去google一下,這個事情其實有很多方案。
經驗比較豐富的研發一定會同意我的一個說法:兩個爭論不休的技術方案,最終能達成一個融合了二者的第三個方案。就好像兩個特別對立的談判方,到最后談判結果是一個融合或者叫妥協的方案。PUSH和PULL也可以二者融合,將做到取長補短,使二者優勢互補。根據推、拉結合順序及結合方式的差異,又分以下四種不同推拉模式:
◆先推后拉——先由服務端PUSH,再由Client端有針對性地拉;
◆先拉后推——根據Client端PULL的信息,服務端進一步主動PUSH與之相關的信息;
◆推中有拉——在數據推送過程中,允許Client隨時中斷并PULL更有針對性的信息;
◆拉中有推——根據Client端PULL的過程,Server主動推送相關的最新信息
幾個開源監控系統的PUSH、PULL選擇
zabbix:帶agent方式。agent主動推送數據到服務端。 從client的角度看,是PUSH數據到Server。
Cacti:SNMP協議,無Client,或者說Client是SNMP Client。從Client角度看,是PULL。
ganglia:從Client角度看,是PUSH。
在我過去生產環境所構造的監控系統里面,我們采用了PUSH和PULL結合的方式來達到及時性、到達率的同時解決。我們站在Client的角度來描述這個解決方案。對于監控項的生效,Web端變更之后立即使用PUSH的方式來通知Client。但這里一定有達到率的問題。比如Client所在服務器死機了、重啟了、當時網絡有問題不可達等等。所以我們在Client端,支持定時PULL。定時去主動聯系Server端,獲取自己應該生效的監控內容。
HASH
怎么突然又說到HASH了呢?HASH先來個概念普及吧!看完概念還是不了解的同學,自行面壁去,你計算機數據結構一定沒好好學。
我說HASH是因為要為后面介紹高可用性架構有關系的。
HASH你別直接拿去搜,用百度的結果就是哈士奇。
關鍵詞可以是哈希。
Hash,一般翻譯做“散列”,也有直接音譯為“哈希”的,就是把任意長度的輸入(又叫做預映射, pre-image),通過散列算法,變換成固定長度的輸出,該輸出就是散列值。這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小于輸入的空間,不同的輸入可能會散列成相同的輸出,所以不可能從散列值來唯一的確定輸入值。簡單的說就是一種將任意長度的消息壓縮到某一固定長度的消息摘要的函數。
Hash在算法里面是很基礎但使用非常廣泛的。特別是在大數據量的情況下。
我這里強調Hash,是想說它的一個作用之一就是散列。把輸入散列到幾個地方去。提到Hash不得不提一個詞叫做一致性Hash,這個算法對于解決緩存命中率有很大好處。在內存緩存、CDN等存儲系統中經常使用。
Hash的精髓之一就是按照某種計算規則,把輸入散列到不同的輸出通道上去。
無狀態和有狀態
我們拿無狀態協議來體驗一下無狀態是個什么概念。
協議的狀態是指下一次傳輸可以“記住”這次傳輸信息的能力。典型的如HTTP協議是不會為了下一次連接而維護這次連接所傳輸的信息,由于Web服務器要面對很多瀏覽器的并發訪問,為了提高Web服務器對并發訪問的處理能力,在設計HTTP協議時規定Web服務器發送HTTP應答報文和文檔時,不保存發出請求的Web瀏覽器進程的任何狀態信息。這有可能出現一個瀏覽器在短短幾秒之內兩次訪問同一對象時,服務器進程不會因為已經給它發過應答報文而不接受第二期服務請求。由于Web服務器不保存發送請求的Web瀏覽器進程的任何信息,因此HTTP協議屬于無狀態協議(Stateless Protocol)。
監控系統里面的HASH和狀態
監控系統對數據的處理,主要是過濾異常數據出來并報警。比如某個服務器的CPU利用率超過了95%,需要報警。但這個時候突然數據處理模塊所在服務器宕機了。那么,這個異常數據很有可能就丟掉了。
監控系統常見的報警條件是: CPU利用率超過95%,算一次異常。如果5分鐘內有3次異常,報警給運維。
這里就有幾個數字需要處理,5分鐘,3次。前面提到的宕機,會導致一次異常數據丟掉了。假設5分鐘內出現了3次,丟掉了一次,那自然不會報警出來。這就是一個有狀態的場景。
有狀態的情況下,做自動切換或者負載均衡,需要把狀態也帶過去才行。
比較典型的還有session的問題。如果web是多臺主機負載均衡的時候,session存本地是會出問題的。因為用戶有可能通過負載均衡的調度,多次請求落在不同的主機上。 本來HTTP協議是無狀態的,支持負載均衡的調度。但因為session這個有狀態的產物,必須要把session放在公共存儲上才行。
結合前面提到的那個架構圖。數據進入到了數據計算和報警模塊。我們如何保證這個數據計算和報警模塊是個高可用的架構。
答案是,把輸入的監控數據Hash到不同的數據計算和報警模塊實例上去,并且最好是無狀態或者弱狀態的計算過程。(未完待續)
【編輯推薦】
【責任編輯:火鳳凰 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
