新浪微博王傳鵬:微博推薦架構的演進(1)
2016-02-20 19:33:33 來源: 王傳鵬 51CTO 評論:0 點擊:
在微博推薦發展的過程中遇到體系方向的變化、業務的不斷更迭、目標的重新樹立,其產品思路、架構以及算法也隨之進行變遷。本文主要闡述在這個過程中推薦架構的演進,從產品目標、算法需求以及技術發展等維度為讀者呈現一個完整的發展脈絡,同時也希望通過這個機會跟大家一起探討業務與技術的相互關系。
2 分層式的2.0
上一節介紹完獨立的1.0,按照架構發展的道路,我們到了分叉路口,一邊是流行的LAMP架構,另一邊是符合廣告、搜索的CELL架構。LAMP架構數據策略分離,腳本語言作為業務開發主要語言,項目快速開發和迭代的首選。CELL結構強調本地流程處理,數據與業務耦合性強,自研的服務以及數據庫較多出現,適用于高性能效果型產品。最終我們選擇兼容兩者,傾向于業務的架構體系。為何如此呢?讓我們再來看看當時的環境。
2.1 環境
微博推薦2.0的時間段是2013年3月份到2014年年底,這段時間內部環境因素是:
1) 當前團隊成員合作已經很長時間,彼此相互熟悉,同時對于技術選型有了一定的共識。
2) 團隊產品進行了聚焦,針對內容/用戶/垂直類三類推薦進行了整理,同時對于場景分別進行了重點劃分:feed流內、正文頁以及PC首頁右側。這種聚焦有利于進行架構統一,同時也為技術爭取了時間。
而外部因素是:
1) 公司對于推薦有了比較明確的定位,提高關系達成以及內容傳播效率,同時為推薦型廣告打好技術探索、場景介入以及用戶體驗的基礎。
2) 推薦領域里,各個公司都紛紛有了對于架構的產出,對于微博推薦有了很好的指導意義。
2.2 架構組成與特點
團隊在執行核心業務實現的時候,不斷演進工具以及框架,構建2.0的目標呼之欲出。
1) 技術目標
與1.0不同,僅僅實現業務需求已經不是2.0的技術目標了,針對完整的推薦流程,我們需要解決:
首先要實現完整的推薦流程,架構覆蓋候選、排序、策略、展示、反饋和評估。
以數據為先,提煉出數據架構。實現數據對比,效果以數據為準;實現數據通道,體現反饋;實現數據落地,承接業務需求。
提供算法方便介入的方式。
既能保證業務的快速迭代和開發,又能支持高效運算。
2) 架構組成
微博推薦2.0的架構如圖5所示,它不再是一個個獨立的系統,也不是會讓開發人員使用不同的技術解決相似的問題。這個架構圖主要包括幾個部分的內容:
應用層:主要承擔推薦策略以及展現方面的工作,其特點在于充分發揮腳本語言的特點響應迭代需求。大部分的推薦內容經過排序之后已經可以展示了,但是由于前端產品策略的設定需要融合、刪選以及重排操作,需要這一層來完成,在技術層面屬于IO密集型的。在技術選型上,早期在原有apache+mod_python基礎上進行了框架開發產生了common_recom_frame。該框架面向的是二次開發者,基于此框架可以很好的實現推薦業務流程。該框架的核心思想是提煉出project、work以及data的三層interface,project針對每一個推薦項目,work針對每個推薦項目中不同推薦方法,而data則是管理下游數據的訪問方法。同時,設定了兩個規范:一個是統一了推薦接口,無論是用戶、內容還是垂直業務;另一個是屏蔽了不同協議數據庫訪問方法,極大提高了開發效率。common_recom_frame框架的誕生基本上解決了產品的各種推薦策略需求,走在了產品的前面。
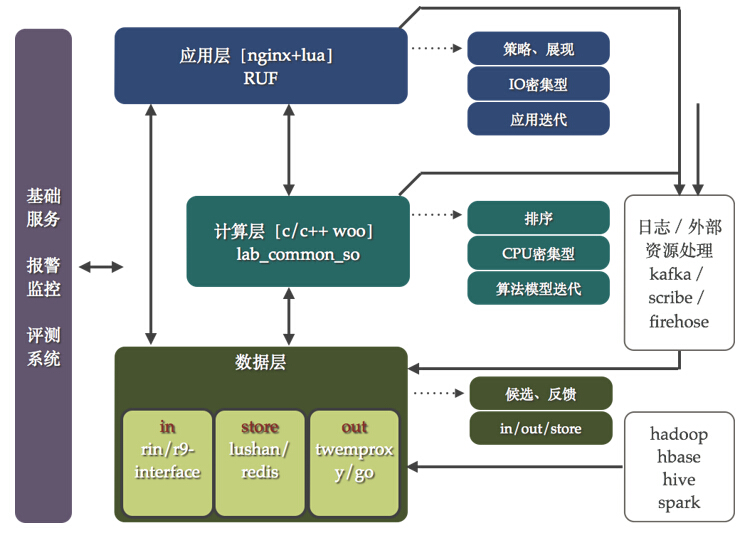
圖5 微博推薦2.0架構示意圖
計算層:主要承擔推薦的排序計算,主要消耗CPU,在這一層給算法提供介入方法,支持算法的模型迭代。在這一層的技術選型上,我們繼承了原有的WOO協議框架,一種基于c/c++開發的內部高效通訊框架。當然也做了不少擴展,依然借用了上面提到的common_recom_frame的思想,在WOO框架基礎上實現了對于project/work/data的管理,提供給二次開發者更為高效的開發工具。在團隊的開源項目中包含這個工具:https://github.com/wbrecom/lab_common_so
數據層:主要承擔推薦的數據流以及存儲工作。數據層的工作主要是解決數據的IN/OUT/STORE問題。其中IN數據如何進入系統,OUT表示數據如何訪問,STORE表示數據如何存。當在進行數據層規劃的時候,又分析了微博推薦的數據特點,可以將其分為兩類:靜態和動態。靜態數據的定義為: 更新需要全量同時頻次較低的大規模數據;動態數據的定義為:動態更新同時頻次較高的增量數據。這樣在IN/OUT/SOTRE的大方向下,同時區分對待靜態和動態數據,產生了RIN/R9-interface、redis/lushan、tmproxy/gout代理的工具或者框架。在這里展開講一下,RIN支持數據動態數據的接入,通過web服務的方式接收數據,后端使用ckestrel進行隊列管理,輔以多服務集群的消費框架,使用者只需要進行自己業務的開發即可快速上線消費動態數據。R9-interface處理靜態數據的接入,推薦的大量靜態數據來源于Hadoop集群的運算,r9-interface框架勇來解決靜態運算[MR、HIVE SQL以及SPARK 運算]的通知、管理以及數據載入。針對推薦數據的存儲,動態數據大量使用了redis集群,靜態數據則使用了lushan集群。對于lushan這個工具在團隊開源項目中也包含了:https://github.com/wbrecom/lushan。tmproxy/gout用來解決數據的OUT問題,gout是一個代理中間件,用來處理推薦中對于數據的動靜結合訪問的需求,減少業務對于后端數據變化帶來的影響。
基礎服務:推薦系統的基礎服務主要包括監控、報警以及評測系統,數據監控系統分為性能以及效果監控兩類,評測系統主要用來進行下線評估,在上線之前對效果有一定預期以及減少無效上線。圖6展示了基礎服務的UI。
圖6 基礎服務系統的UI
3) 特點
優點是:
- 支撐完整的推薦流程,對于數據方面擁有統一的處理方法
- 在兼顧業務功能快速實現的同時保證了效果技術的不斷深化
- 給算法提供了很好的支持
- 提出以數據為先的思想,可以全面對比效果,推薦效果不斷得以提升
- 封層體系易于部署以及QA介入進行測試
而不足是:
- 和推薦核心有一定的距離,并沒有完全為推薦量身定做
- 將推薦的策略算法完全交給了開發者,不利于推薦通用型
- 對于算法的訓練并沒有涉及,僅僅是一個線上投放系統,不足以構成完整的推薦體系
2.3 成果
微博推薦2.0的誕生產生很好的收益,其成果如下:
1) 微博推薦的核心業務均在該體系下完成:正文頁推薦、趨勢用戶推薦、趨勢內容推薦、各個場景下的用戶推薦、粉絲經濟的粉條、賬號推薦等等產品
2) 誕生了lab_common_so的基礎框架,并進行了開源
3) 誕生了靜態存儲集群解決方案lushan,并進行了開源
4) RUF框架的誕生極大提升了業務生產效率,同時也為openresty社區做出一定貢獻
分享到:
 收藏
收藏
收藏
