新浪微博王傳鵬:微博推薦架構的演進(1)
2016-02-20 19:33:33 來源: 王傳鵬 51CTO 評論:0 點擊:
在微博推薦發展的過程中遇到體系方向的變化、業務的不斷更迭、目標的重新樹立,其產品思路、架構以及算法也隨之進行變遷。本文主要闡述在這個過程中推薦架構的演進,從產品目標、算法需求以及技術發展等維度為讀者呈現一個完整的發展脈絡,同時也希望通過這個機會跟大家一起探討業務與技術的相互關系。

王傳鵬 新浪微博推薦及廣告技術總監
| 王傳鵬,WOT峰會特邀嘉賓,曾為第七屆WOT移動互聯網開發者大會的特約講師,也是本屆“互聯網+”時代大數據技術峰會的聯合出品人之一。2006年從北航畢業,然后加入霍尼韋爾北京研中心做工程,之后同合伙人一起創辦云存儲網絡硬盤(99盤)。在公司被收購后,加入當當網負責推薦和廣告工作。于2011年加入新浪微博商業產品部,負責推薦和廣告,直至現在。 |
引言
微博(Weibo)是一種通過關注機制分享簡短實時信息的廣播式社交網絡平臺。微博用戶通過關注來訂閱內容,在這種場景下,推薦系統可以很好地和訂閱分發體系進行融合,相互促進。微博兩個核心基礎點:一是用戶關系構建,二是內容傳播,微博推薦一直致力于優化這兩點,促進微博發展。如圖1所示:
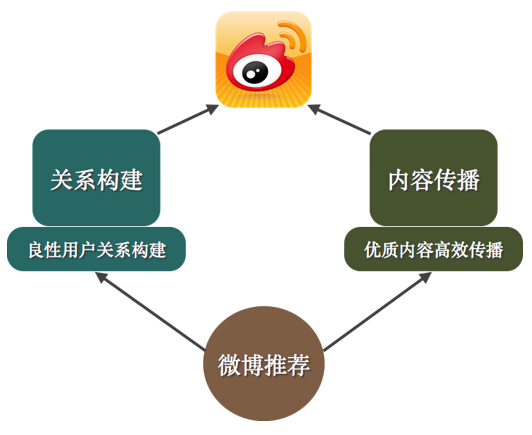
圖1 微博推薦的使命
在微博推薦發展的過程中遇到體系方向的變化、業務的不斷更迭、目標的重新樹立,其產品思路、架構以及算法也隨之進行變遷。本文主要闡述在這個過程中推薦架構的演進,從產品目標、算法需求以及技術發展等維度為讀者呈現一個完整的發展脈絡,同時也希望通過這個機會跟大家一起探討業務與技術的相互關系。
為了便于理解微博推薦架構演進,在介紹之前需要陳述一下微博推薦在流程上的構成,其實這個和微博本身沒有關系,理論上業內推薦所存在的流程基本都是相同的。如圖2所示,推薦是為了解決用戶與item之間的關系,將用戶感興趣的item推薦給他/她。那么,一個item被推薦出來會經過候選、排序、策略、展示、反饋到評估再改變候選等等形成一個完整的回路。
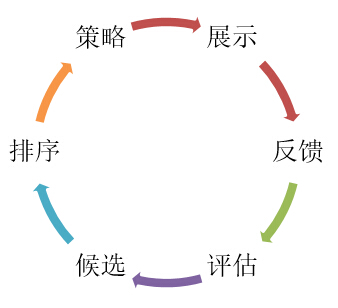
圖2推薦的鏈路
在上述整體流程的基礎上,微博推薦架構經歷了如圖3所示的三個階段:
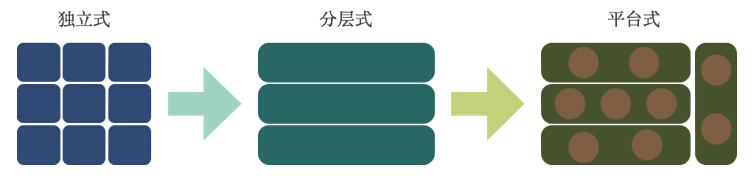
圖3 微博推薦架構的三個階段
通常架構的產生都會來自于團隊和業務環境,源于環境因素而致力于解決環境中的問題,架構形成會帶著較為強烈的特點,在其實施中會產生交給針對性的效果。本文將從環境因素、架構組成與特點以及實施效果這三個方面進行闡述微博推薦的三個階段。
1 獨立式的1.0
1.1 環境
影響架構形成的環境因素可以分為內部環境因素以及外部環境因素。內部因素主要是團隊及其成員相關內容,而外部因素主要來自于外部門、整個公司或者整個行業領域。
微博推薦1.0的這段時間是從2011年7月份到2013年2月份左右,其主要的目標就是實現當前的業務需求。對于獨立式的解釋:每一個業務項目都是一套完整架構流程,架構之間相對獨立,甚至包括技術棧。之所以稱之為獨立式其內部因素有幾點:
1) 當時團隊是一個新團隊,成員也相對較新,相互的合作不多,缺乏推薦領域整體性經驗。
2) 團隊成員對于推薦架構都有自己的一些或多或少的理解,但是對于在當前場景下的微博推薦架構,共識并沒有形成。
當然起決定性因素的還是外部環境,是因為內部原因還是比較好協調和進化的。當時的外部環境因素包括:
1) 項目需求很多,在當時一個5人團隊并行開發的項目平均在3-5個左右,當然最重要的因素是當時的微博產品正處于高速發展期,很多地方都需要微博推薦的支撐。同時,項目周期也很短,排期倉促,很難有時間進行細致的整理和抽象。典型產品包括:微吧、微群、微刊、微話題、用戶以及內容排序等等。
2) 團隊是一個支撐性的,絕大部分需求來自于外部團隊,各個外部團隊不同的產品方向也導致疲于應付需求。
3) 當時業內的推薦架構也有不同的發展方向,大家都在嘗試摸索一些符合自身發展的架構思路。
由于上述的那些原因,通常我們面對一個接一個的項目時,都會根據自己的理解使用熟悉的技術棧來搭建流程,這樣形成了一個又一個的獨立架構。
1.2 架構組成與特點
上節中提到了獨立架構形成的原因,大家可能覺得架構組成沒有必要去描述了,這是不對的,事實上后來的分層以及平臺架構的基礎恰恰都來源于這個階段,沒有這個階段團隊不斷踩坑總結就沒有因地制宜產生的后續進化。因此,我們需要為大家剖析一下推薦1.0的架構組成與特點。
1) 技術目標
參考圖2所示,以業務實現為主要目標的微博推薦1.0,沒有建立起完整的反饋以及評估體系,同時排序也是被策略取代,那么講主要的重點體現到了候選、策略以及展現上。上述推薦流程被轉化為:候選策略展現簡單形態。
2) 架構組成
如圖4所示,我們試圖將每個項目的架構能夠在圖中表達出來,在真正的實施過程中,每一個項目負責人會選擇使用apache+mod_python作為服務架構同時,使用redis作為存儲選型。在一些特定的項目中,引入了復雜運算從而誕生了c/c++的服務框架woo;同時,對于數據的存儲要求特型化的項目中又自己研發了一系列的db,比如早期存儲靜態數據的mapdb,存儲key-list的keylistdb等等。當然,在部署中會比下圖更加隨意一些,一個項目幾臺服務器部署好微博服務提供http請求,然后再找幾個服務器安裝redis作為數據支撐,來源數據和業務方定好規則使用rsync傳輸就OK了,大部分策略在python中實現。
圖中可以看到主要的技術棧:
- web服務:apache+mod_python,后來發展成為社區更為完善的mod_wsgi。使用python作為WEB開發語言主要是因為平時處理數據使用的都是python,同時上手快,學習曲線平緩。
- 運算服務:c/c++,形成woo內部服務框架
- db:redis/mapdb/keylistdb等等,分為兩種存儲方法:redis以及自研型
- 數據來源:rsync文件傳輸,firehose作為微博相關內容來源[微博內部使用的一種數據隊列]
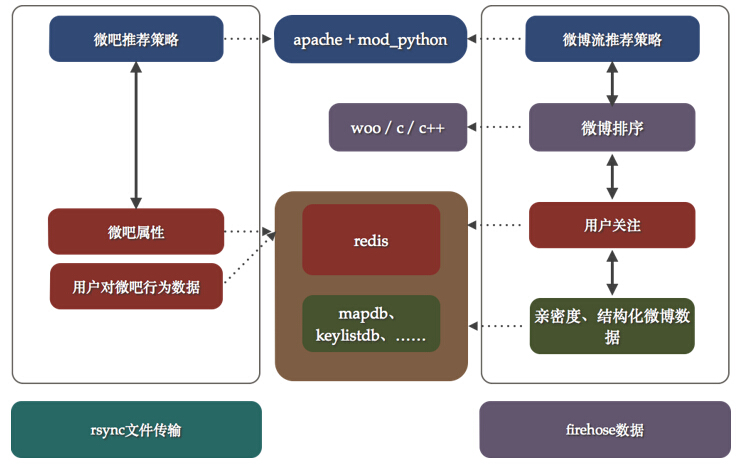
圖4 微博推薦1.0架構簡圖
3) 架構特點
將架構特點劃分為優點和缺點進行描述。那么優點是:
- 簡單,易于實現,不需要額外的基礎支撐
- 利于業務的功能快速實現
- 利于多業務并行開展,相互不影響
而不足是:
- 推薦流程不完整,缺乏反饋、評估等等重要內容,對于數據方面也極度缺乏統一處理方法
- 沒有提供給算法相關的支撐,很難將推薦做的深入
- 幾乎無法進行專業運維
- QA的測試僅僅能到功能層面,模塊級別的測試幾乎不可能,因為太過于分散
- 很難進行團隊協作,不利于項目的分解
1.3 成果
盡管存在諸多的缺點,但是在其發展的過程中,也給后面的架構優化奠定了基礎,其成果如下:
1) 在微博高速發展的過程中,滿足了微博對于推薦的業務支撐要求,在這段時期里面共完成二十多個獨立項目。
2) 誕生了woo的基礎框架,后面的內部高效運算框架來源于此
3) 誕生了mapdb的靜態存儲,成為后期微博推薦靜態存儲的雛形
4) web應用層的不斷需求的總結,組建形成推薦通用應用框架
2 分層式的2.0
上一節介紹完獨立的1.0,按照架構發展的道路,我們到了分叉路口,一邊是流行的LAMP架構,另一邊是符合廣告、搜索的CELL架構。LAMP架構數據策略分離,腳本語言作為業務開發主要語言,項目快速開發和迭代的首選。CELL結構強調本地流程處理,數據與業務耦合性強,自研的服務以及數據庫較多出現,適用于高性能效果型產品。最終我們選擇兼容兩者,傾向于業務的架構體系。為何如此呢?讓我們再來看看當時的環境。
2.1 環境
微博推薦2.0的時間段是2013年3月份到2014年年底,這段時間內部環境因素是:
1) 當前團隊成員合作已經很長時間,彼此相互熟悉,同時對于技術選型有了一定的共識。
2) 團隊產品進行了聚焦,針對內容/用戶/垂直類三類推薦進行了整理,同時對于場景分別進行了重點劃分:feed流內、正文頁以及PC首頁右側。這種聚焦有利于進行架構統一,同時也為技術爭取了時間。
而外部因素是:
1) 公司對于推薦有了比較明確的定位,提高關系達成以及內容傳播效率,同時為推薦型廣告打好技術探索、場景介入以及用戶體驗的基礎。
2) 推薦領域里,各個公司都紛紛有了對于架構的產出,對于微博推薦有了很好的指導意義。
2.2 架構組成與特點
團隊在執行核心業務實現的時候,不斷演進工具以及框架,構建2.0的目標呼之欲出。
1) 技術目標
與1.0不同,僅僅實現業務需求已經不是2.0的技術目標了,針對完整的推薦流程,我們需要解決:
首先要實現完整的推薦流程,架構覆蓋候選、排序、策略、展示、反饋和評估。
以數據為先,提煉出數據架構。實現數據對比,效果以數據為準;實現數據通道,體現反饋;實現數據落地,承接業務需求。
提供算法方便介入的方式。
既能保證業務的快速迭代和開發,又能支持高效運算。
2) 架構組成
微博推薦2.0的架構如圖5所示,它不再是一個個獨立的系統,也不是會讓開發人員使用不同的技術解決相似的問題。這個架構圖主要包括幾個部分的內容:
應用層:主要承擔推薦策略以及展現方面的工作,其特點在于充分發揮腳本語言的特點響應迭代需求。大部分的推薦內容經過排序之后已經可以展示了,但是由于前端產品策略的設定需要融合、刪選以及重排操作,需要這一層來完成,在技術層面屬于IO密集型的。在技術選型上,早期在原有apache+mod_python基礎上進行了框架開發產生了common_recom_frame。該框架面向的是二次開發者,基于此框架可以很好的實現推薦業務流程。該框架的核心思想是提煉出project、work以及data的三層interface,project針對每一個推薦項目,work針對每個推薦項目中不同推薦方法,而data則是管理下游數據的訪問方法。同時,設定了兩個規范:一個是統一了推薦接口,無論是用戶、內容還是垂直業務;另一個是屏蔽了不同協議數據庫訪問方法,極大提高了開發效率。common_recom_frame框架的誕生基本上解決了產品的各種推薦策略需求,走在了產品的前面。
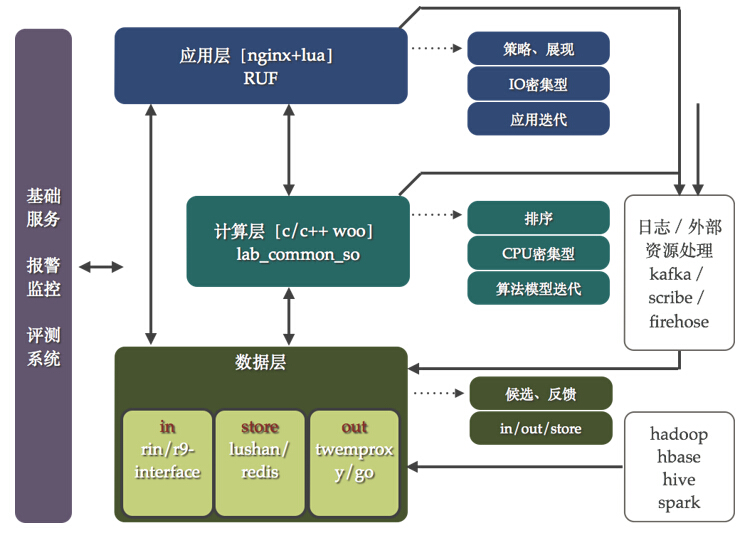
圖5 微博推薦2.0架構示意圖
計算層:主要承擔推薦的排序計算,主要消耗CPU,在這一層給算法提供介入方法,支持算法的模型迭代。在這一層的技術選型上,我們繼承了原有的WOO協議框架,一種基于c/c++開發的內部高效通訊框架。當然也做了不少擴展,依然借用了上面提到的common_recom_frame的思想,在WOO框架基礎上實現了對于project/work/data的管理,提供給二次開發者更為高效的開發工具。在團隊的開源項目中包含這個工具:https://github.com/wbrecom/lab_common_so
數據層:主要承擔推薦的數據流以及存儲工作。數據層的工作主要是解決數據的IN/OUT/STORE問題。其中IN數據如何進入系統,OUT表示數據如何訪問,STORE表示數據如何存。當在進行數據層規劃的時候,又分析了微博推薦的數據特點,可以將其分為兩類:靜態和動態。靜態數據的定義為: 更新需要全量同時頻次較低的大規模數據;動態數據的定義為:動態更新同時頻次較高的增量數據。這樣在IN/OUT/SOTRE的大方向下,同時區分對待靜態和動態數據,產生了RIN/R9-interface、redis/lushan、tmproxy/gout代理的工具或者框架。在這里展開講一下,RIN支持數據動態數據的接入,通過web服務的方式接收數據,后端使用ckestrel進行隊列管理,輔以多服務集群的消費框架,使用者只需要進行自己業務的開發即可快速上線消費動態數據。R9-interface處理靜態數據的接入,推薦的大量靜態數據來源于Hadoop集群的運算,r9-interface框架勇來解決靜態運算[MR、HIVE SQL以及SPARK 運算]的通知、管理以及數據載入。針對推薦數據的存儲,動態數據大量使用了redis集群,靜態數據則使用了lushan集群。對于lushan這個工具在團隊開源項目中也包含了:https://github.com/wbrecom/lushan。tmproxy/gout用來解決數據的OUT問題,gout是一個代理中間件,用來處理推薦中對于數據的動靜結合訪問的需求,減少業務對于后端數據變化帶來的影響。
基礎服務:推薦系統的基礎服務主要包括監控、報警以及評測系統,數據監控系統分為性能以及效果監控兩類,評測系統主要用來進行下線評估,在上線之前對效果有一定預期以及減少無效上線。圖6展示了基礎服務的UI。
圖6 基礎服務系統的UI
3) 特點
優點是:
- 支撐完整的推薦流程,對于數據方面擁有統一的處理方法
- 在兼顧業務功能快速實現的同時保證了效果技術的不斷深化
- 給算法提供了很好的支持
- 提出以數據為先的思想,可以全面對比效果,推薦效果不斷得以提升
- 封層體系易于部署以及QA介入進行測試
而不足是:
- 和推薦核心有一定的距離,并沒有完全為推薦量身定做
- 將推薦的策略算法完全交給了開發者,不利于推薦通用型
- 對于算法的訓練并沒有涉及,僅僅是一個線上投放系統,不足以構成完整的推薦體系
2.3 成果
微博推薦2.0的誕生產生很好的收益,其成果如下:
1) 微博推薦的核心業務均在該體系下完成:正文頁推薦、趨勢用戶推薦、趨勢內容推薦、各個場景下的用戶推薦、粉絲經濟的粉條、賬號推薦等等產品
2) 誕生了lab_common_so的基礎框架,并進行了開源
3) 誕生了靜態存儲集群解決方案lushan,并進行了開源
4) RUF框架的誕生極大提升了業務生產效率,同時也為openresty社區做出一定貢獻
3 平臺式的3.0
上節中描述2.0的時候提到了一個重要不足是“和推薦核心有一定的距離,并沒有完全為推薦量身定做”,我們希望能夠在推薦3.0中解決它,這個不足會帶來什么問題,以及為何在已經滿足業務需求的同時推薦的架構再次往前發展呢?那么接下來為各位展現微博推薦平臺式的3.0設計,我們還是先看看所處的環境。
3.1 環境
微博推薦3.0的時間段是2014年底至今,當前的內部環境因素是:
1) 推薦產品不在擴張,對效果更為看重,將工作重點從業務開發和迭代轉化為以效果為目標的技術迭代。
2) 新項目或者迭代推薦業務的時候發現重復的事情很多,而架構沒有解決,工作存在冗余。
而外部因素是:
1) 公司也從業務擴展轉變為效率為先,提升用戶體驗以及內容質量上來。
2) 微博推薦在推薦技術環節距離領域內有一定距離,當下有條件進行追趕。
3.2架構組成與特點
當前的環境也能體現出3.0的技術目標:
1) 技術目標
與2.0不同,全覆蓋推薦流程已經不是3.0的目標,其目標是:
抽象出推薦流程中對于候選/排序/訓練/反饋的通用方法來
推薦是一個算法數據問題,應該以一個算法的角度構建推薦系統,因此需要更為貼近算法策略
2) 架構組成
如圖7所示,是微博推薦3.0的架構,也是當前實行的架構體系,大家其實可以發現,這是基于2.0 發展起來的,既然還保留了大量2.0中使用的分層體系以及工具框架。在這里重點描述幾個差異:
兩個標準:一個是針對應用層,作為整體框架輸出,應用層設定all in one 接口標準,其標準包含了輸入以及輸出參數;另外一個是針對動態輸入rin,由于離線計算我們可以確定結構,因此一個輸入層工具r9-interface不需要設定規范,但是rin是需要進行標準設定,從屬性/交互數據/日志等等層面進行劃分。
計算層增加對于候選的標準生成方法:Artemis內容候選模塊,item-cands用戶候選模塊、……,在項目開發中只需要選擇這些候選生成方法即可。
增加了策略平臺EROS,解決算法模型的問題。EROS主要的幾個功能是:1)訓練模型 2)特征選取 3)上線對比測試。
數據層中的r9-interface以及rin增加對于候選的生成方法,在線以及離線使用推薦通用策略生成結果。
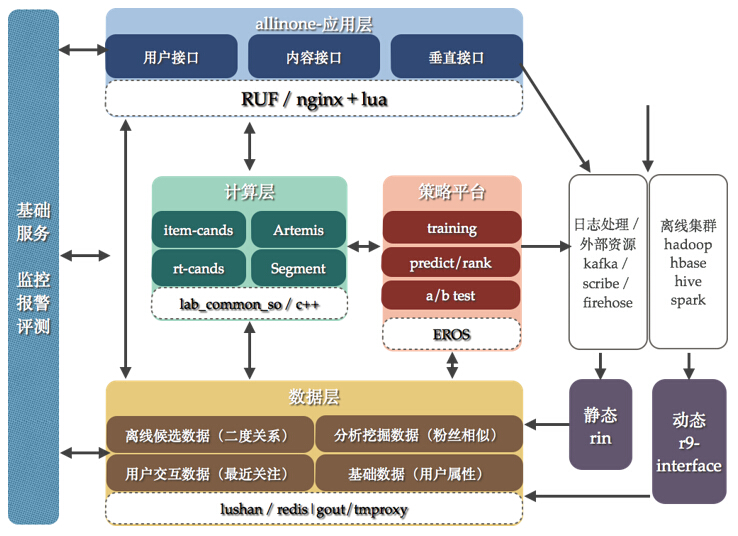
圖7 微博推薦3.0的架構示意圖
3) 特點
主要描述其優勢:
繼承了原有2.0的特點,保留了其優勢
對于推薦理解更為深入,結合更為緊密
解決了推薦候選/排序/訓練的算法最重要問題
3.3 成果
微博推薦3.0的誕生,其成果如下:
1) 微博推薦的核心業務會逐步遷移到該體系下,以算法數據作為驅動,提升效果
2) 誕生了EROS的訓練流程,提出了訓練的標準方法
3) 針對推薦設定了標準的輸入輸出方法
4) 針對候選,產生了具有抽象意義的推薦方法集合
4 總結
上文中對微博推薦架構演進做了較為詳實的介紹,在這個演進的過程團隊以及個人收益很大,技術與業務的關系在架構中得到了很好的體現。有幾點可以跟大家分享的是:
1) 技術來源于業務同時提升業務發展,業務發展又反過來推動技術的前進,他們是一個相互影響相互促進的關系。和業務共同發展的技術才是有生命力的。
2) 技術架構的選型建議是尋找當前最短路徑,然后進行不斷優化迭代,一口氣吃撐是不現實的,也是不合理的。
3) 推廣某個框架和工具最好的方式不是行政命令也不是請客吃飯,而是的大家都是參與者,如同開源項目,每個人都是它的主人,這樣人人維護,人人使用。
4) 團隊崇尚簡單可依靠,它說起來容易做起來難,不過有一個好方法就是懂得自己不應該做什么,而不是應該做什么。
5) 說到推薦這個特殊領域上來,設定目標,跟蹤目標很重要,把數據和目標擺出來,產品、架構以及算法都會想辦法去解決的。
最后,跟大家推薦一下微博推薦的官方博客:http://www.wbrecom.com/ 歡迎大家提出建議和建議。感謝大家對于微博推薦以及微博的關心和愛護,謝謝!
【責任編輯:林師授 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
