自動化持續部署的三種反模式及解決方案(1)
2016-02-20 19:33:43 來源: 老王 互聯網運維雜談 評論:0 點擊:
自動化持續部署是業界最佳實踐,以此為目標,能優化IT模式。我一直強調持續部署是IT交付的核心能力,直接關聯到研發 測試和運維多個團隊,可以成為一個運維的核心平臺。自動化部署能力的高與低,能映射出IT能力的諸多方面的問題,比如說流程上 環境管理上 服務耦合上 平臺能力上等等。
一旦將應用程序部署到了試運行環境,我們常常會發現新的缺陷。遺憾的是,我們常常沒有時間修復所有問題,因為最后期限馬上就到了,而且項目進行到這個階段時,推遲發布日期是不能被人接受的。所以,大多數嚴重缺陷被匆忙修復,而為了安全起見,項目經理會保存一份已知缺陷列表,可是當下一次發布開始時,這些缺陷的優先級還是常常被排得很低。
有的時候,情況會比這還糟,以下這些事情會使與發布相關的問題惡化:
◆假如一個應用程序是全新開發的,那么第一次將它部署到試運行環境時,可能會非常棘手。
◆發布周期越長,開發團隊在部署前作出錯誤假設的時間就越長,修復這些問題的時間也就越長。
◆交付過程被劃分到開發、DBA、運維、測試等部門的那些大型組織中,各部門之間的協作成本可能會非常高,有時甚至會將發布過程拖上“地獄列車”。此時為了完成某個部署任務(更糟糕的情況是為了解決部署過程中出現的問題),開發人員、測試人員和運維人員總是高舉著問題單(不斷地互發電子郵件)。
◆開發環境與生產環境差異性越大,開發過程中所做的那些假設與現實之間的差距就越大。雖然很難量化,但我敢說,如果在Windows系統上開發軟件,而最終要部署在Solaris集群上,那么你會遇到很多意想不到的事情。
◆如果應用程序是由用戶自行安裝的(你可能沒有太多權限來對用戶的環境進行操作),或者其中的某些組件不在企業控制范圍之內,此時可能需要很多額外的測試工作。
三、反模式3:生產環境的手工配置管理
很多組織通過專門的運維團隊來管理生產環境的配置。如果需要修改一些東西,比如修改數據庫的連接配置或者增加應用服務器線程池中的線程數,就由這個團隊登錄到生產服務器上進行手工修改。如果把這樣一個修改記錄下來,那么就相當于是變更管理數據庫中的一條記錄了。這種反模式的特征如下:
◆多次部署到試運行環境都非常成功,但當部署到生產環境時就失敗。
◆集群中各節點的行為有所不同。例如,與其他節點相比,某個節點所承擔的負載少一些,或者處理請求的時間花得多一些。
◆運維團隊需要較長時間為每次發布準備環境。
◆系統無法回滾到之前部署的某個配置,這些配置包括操作系統、應用服務器、關系型數據庫管理系統、Web服務器或其他基礎設施設置。
◆不知道從什么時候起,集群中的某些服務器所用的操作系統、第三方基礎設施、依賴庫的版本或補丁級別就不同了。
◆直接修改生產環境上的配置來改變系統配置。
運維的關鍵實踐之一就是配置管理,其責任之一就是讓你能夠重復地創建那些你開發的應用程序所依賴的每個基礎設施。這意味著操作系統、補丁級別、操作系 統配置、應用程序所依賴的其他軟件及其配置、基礎設施的配置等都應該處于受控狀態。你應該具有重建生產環境的能力,最好是能通過自動化的方式重建生產環境。
我們也應該有能力在部署出錯時,通過同一個自動化過程將系統回滾到之前的版本。
四、問題的答案:自動化部署
實現一個完善的自動構建、部署、測試和發布系統。為了讓這個系統能夠良好運行下去,我們還幫助他們采用了一些必要的開發實踐和技術(大系統做小/維服務/灰度能力等等)。如何使用部署流水線,將高度自動化的測試和部署以及全面的配置管理結合在一起,實現一鍵式軟件發布。也就是說,只需要點擊一下鼠標,就可以將軟件部署到任何目標環境,包括開發環境、測試環境或生產環境。
——————以上觀點摘自《持續交付》
見到的通行做法是三種:
1.自動化腳本來封裝,用expect+ssh;
2.用配置管理工具來實現;
3.在Jenkins中寫插件來實現。
但我依然覺得,這不是我要的可視化+自動化部署系統,一般都選擇自己實現。
1.YY包部署系統
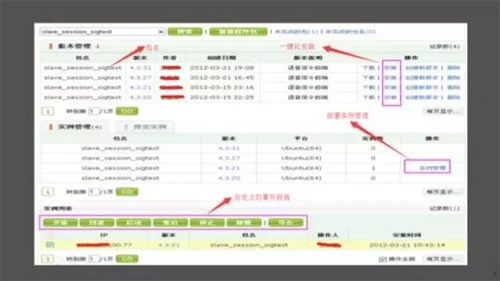
缺點:
A、對配置管理支持的不是很好
B、環境管理能力很弱
C、沒有以應用維度進行管理
2.UC的持續部署系統
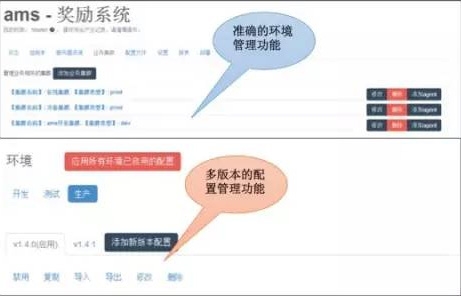
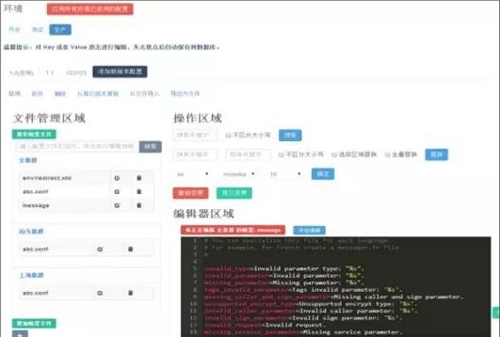
這是利用公司另外一個系統基礎上修改過來的,支持了游戲業務的特殊發布場景,做了一些優化,但還是有一些缺點。
缺點:
A、應用程序和底層Agent的耦合太重,Agent的異常會影響應用程序的工作。
B、系統架構設計很復雜,涉及組件過多,基于CF修改過來的。
C、基于CF的PAAS平臺每支持一種語言就要重新開發。
D、對于包的抽象能力不夠,管理能力需要在Agent層封裝。當然這個能力可以更上層實現,兼容各種操作場景。
3.新持續部署系統(doing)
基于包的全新抽象,支持各種語言;開放包的管理能力給用戶,適應各種場景;支持對包/配置/環境的可視化管理;支持灰度,支持快速回滾....等等。
【編輯推薦】
【責任編輯:火鳳凰 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
