突發重大事故,我們運維這樣進行處理(1)
2016-02-20 19:34:04 來源: 余何 高效運維 評論:0 點擊:
在我們組織內部有兩個處理流程,對于突發重大事件,有專門召集各方聯合診斷的UIOC(ugency incident office center),緊急事故處理中心。而一般事件,我們通過事件管理通道滿足用戶需求。UIOC的目的在于快速調動IT資源,高效協同診斷事件,在這個過程中,開發關注應用邏輯、運營關注業務影響、運維關注底層資源、DBA關注數據庫。本文是運維事件處理經驗的干貨談。

作者介紹
余何,外號:眾神的大師兄,運維心靈捕手,十余年IT金融運維經驗,一直任職于某世界100強企業,參與并主導過各大神秘項目,熱愛開源、感悟運維、癡迷于IT技術。
前言
It is the time you have wasted on your rose that makes your rose so important.
這是平凡的世界,不平凡的運維專欄的第一期,我很難以一種感性的方式告訴別人運維是做什么的,以至于對不同人會有不同的譬喻。
對于父母,運維是當前世界上很穩定的工作(讓老人安心)。
對于妻子,運維是計算機世界的特工組織(熬夜不歸的好理由)。
對于朋友,運維并不是幫人裝殺毒軟件(告訴別人它不是什么也很重要)。
對于業內人士,運維是可用率99.99%(我覺得以后要換一種方式)。
對于公司老板,運維是一門并不需要知道它有多精彩,但必須重視的崗位(這真的很難,也很矛盾)。
好了,讓我們開啟今天的主題,運維事件處理經驗談。

運維是一朵需要花時間照料的玫瑰
UIOC
為了保證可用率99.99%,除了在應用架構、資源容量上做足功夫外,運維人員還要面對一個事實,那就是異常、故障、突發事件總會發生,這在管理上必須有一個流程方法來應對之。
在我們組織內部有兩個處理流程,對于突發重大事件,有專門召集各方聯合診斷的UIOC(ugency incident office center),緊急事故處理中心。而一般事件,我們通過事件管理通道滿足用戶需求。
多團隊合作
UIOC的目的在于快速調動IT資源,高效協同診斷事件,在這個過程中,開發關注應用邏輯、運營關注業務影響、運維關注底層資源、DBA關注數據庫。
流程啟動的第一步是將大家召集就位。溝通工具、渠道有多種,面對面溝通、郵件列表、即時通訊、視頻會議等,不同團隊類型有不同的處理習慣。但在事前,我們就應當將這些通道提前建立,并驗證隨時可用。
UIOC是一個聯合診斷、積極配合過程,通常會有一個經驗豐富的人員來現場指揮、協調各團隊間的工作。

UIOC溝通工具很重要
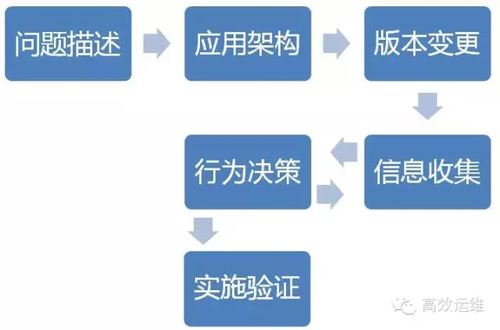
UIOC六步驟
UIOC流程啟動后,如沒有統一管理,則很容易陷入到一片混亂中,我們一般會參照下面五點次序進行問題分析:
1.問題描述
啟動UIOC后,會對問題、異常進行一個簡單描述,如xx系統的xx功能無法使用。
另外,高層會關注業務影響,在這個步驟中,運營人員應當迅速的抽取出業務變化率。
2.應用架構
在問題、業務影響描述清楚后,下一步是系統負責人對應用的整體部署架構進行說明(對于問題所在模塊一目了然的這步可省略)。
這個整體部署架構中包括了主要的配置信息、關聯方等,其主要目的在于縮小問題范圍。
3.版本變更
依據應用架構的輸出來判斷在這個范圍內是否有組件版本發布、基礎資源變更。
大部分故障都是由“變”而起,不是外部(訪問量、安全攻擊),就是內部(版本、變更)。
該步驟幫助我們發現內部變化,如若找到相關影響對象,可以考慮準備回滾步驟、方案。
4.信息收集
以上三步應當是習慣性地快速完成, 如仍無法準確定位到問題點的話,極有可能陷入到僵持狀態中。
信息收集階段,各團隊開始各自挖礦,開發人員查看用戶訪問量、應用異常日志,運維人員檢查基礎資源情況,包括性能數據、日志信息,DBA檢查數據庫等待事件、top sql等,再將各自發現的可疑點共享出來,盡可能形成問題關聯,比如存儲發現IO延時比較高,請DBA確認是否有影響(不是所有的延時都影響數據庫)。
5.行為決策
UIOC強調的是快速恢復,而不是問題分析,亦即找到問題點后可快速采取恢復方案,而不是將時間耗費在窮根問底。
UIOC準確的說是發現問題點在哪里,而不是回答為什么會有這個問題點,對于已發現的問題點,應當問:
◆是否可主備切換
◆是否可功能降級
◆是否可快速擴容
◆是否可版本回滾
在該步驟中確定快速恢復方案。
6.實施驗證
在決策完畢后,實施方案,并做好驗證,確保系統恢復正常。
事件處理
事件處理的是一些相對UIOC的緊急度要低、影響面較小的異常。在我們組織內部,對計算、存儲、網絡以及中間件的事件團隊進行了整合,因此事件量大,涉及范圍廣,在這里介紹一些通用方法來幫助一線人員。
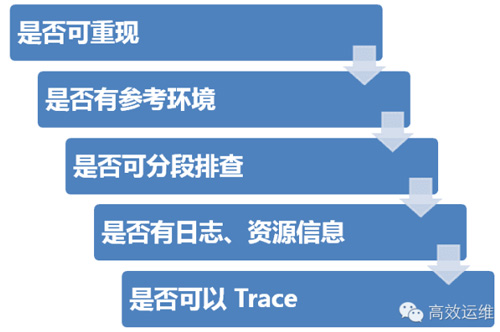
通用方法
1.是否可重現
問題是否可重現對于快速解決問題來說非常重要,但開發人員說我可以立即重現這個問題,好了,運維一線同事請放心,我們總有辦法或工具幫助我們定位到問題點。
最怕的是問題出現之后就不會再有了,需要追溯原因,或者說問題的重現需要準備大量資源,比如特定時間段出現,我們要考慮部署相關工具,例如tcpdump抓包。
2.是否有參考環境
幫助你進一步快速解決問題的是一個參照物,例如一個子系統有多套環境,stg1、stg2,有參照物意味著你快速定位問題又進了一步。
3.是否可分段排查
問題是否可以分段(類似于網絡異常)
找到路徑上的懷疑項,通過組件替換、繞行以及驗證等方式排除。
是否有日志、資源信息。
在第三步先是縮小問題范圍,之后就是對此范圍內的組件進行日志、資源信息檢查,例如中間件日志、Windows事件管理器等。
在這個過程中發現的信息可求助于社區、百度、谷歌尋找解決答案,如果有廠商服務支持,也可以將這些信息提交給后方。
基礎資源信息中關于性能的部分,如果組織內監控管理做得完善,那么這些異常告警會提前發出,也有一個集中、易用的可視化界面查看。
5.是否可以Trace
Trace意味著對問題點的活動數據進行采集或者全量查看。
Trace的使用要謹慎,Trace會影響到組件性能,甚至導致其異常退出,應當盡量避免在生產環境使用。
其包括的步驟包括:
應用服務器Debug開關
tcpdump抓包
strace系統調用
systemtap探針
heapdump內存分析
應該避免
1.碎片干擾
作為運維人員,一定要避免掉入到碎片干擾的陷阱中。
有時候開發人員并不會向你描述問題,而是拋出一段Exception stack(他也是專業人士)。
如果你不弄清楚問題,不追溯源頭,而直接陷入到類似的Exception stack中,有時可以很快解決問題,但有時你將走一段彎路,最終你會發現問題根本原因和這個碎片一點關系都沒有。
正確的做法是問題現象+異常信息,對于問題的快速診斷,二者缺一不可。
2.地毯掃蕩
在上層壓力下很容易出現地毯掃蕩情況,對所有組件的所有配置進行一次掃蕩檢查,例如從網絡設備、到物理機器、虛擬機、操作系統、中間件,這種情況也應當避免。

上層壓力,下層疏導
3.消極配合
地毯掃蕩和消極配合看似是矛盾的,積極配合看似就是地毯掃蕩,當別人提出問題,希望你檢查你所負責的相關資源時,你就陷入到了地毯掃蕩之中。
總結而來,我們應該避免地毯掃蕩,而避免的方法是遵循的問題處理方法論,將問題范圍縮小到一定程度才開始進行地毯掃蕩的。而對關聯他的團隊,我們應當是一個積極的配合態度。
4.無所不能
越是經驗豐富、技術實力強的同事越容易陷入到這里。當他們找到問題點時,會竭盡全力的用各種高難度技術手段來幫助解決,例如在網絡上無數次nat,在操作系統上hack掉問題點等,而其無意中卻埋下了一個坑。
這些技術手段雖然可解決問題,但有可能增加運維復雜度、也有可能存在未驗證的缺陷風險。我們并不是無所不能,無所不能應當控制在規范標準之內,或者放在研發驗證之中。

我們不是無所不能的
如何一起愉快地發展
“高效運維”公眾號(如下二維碼)值得您的關注,作為高效運維系列微信群的唯一官方公眾號,每周發表多篇干貨滿滿的原創好文:來自于系列群的討論精華、運維講壇線上精彩分享及群友原創。“高效運維”也是互聯網專欄《高效運維最佳實踐》及運維2.0官方公眾號。

提示:目前高效運維新群已經建立,歡迎加入。您可添加蕭田國個人微信號xiaotianguo8 為好友,進行申請,請備注“申請入群”。
重要提示:除非事先獲得授權,請在本公眾號發布2天后,才能轉載本文。尊重知識,請必須全文轉載,并包括本行。
【編輯推薦】
【責任編輯:武曉燕 TEL:(010)68476606】
上一篇:百度如何優化多數據中心的帶寬成本?(1)
下一篇:Redis Cluster遷移遇到的各種運維坑及解決方案(1)
分享到:
 收藏
收藏
收藏
