詳解數據中心的運維自動化和DevOps(1)
2016-02-20 19:34:08 來源: 智錦 高效運維 評論:0 點擊:
現在“運維自動化”、“云計算”、“DevOps”很熱,也有很多解釋,但很多人的理解是狹義的甚至錯誤的。本期分享嘉賓智錦將分享其在大型互聯網企業和大型傳統行業的工作感受,并從整個數據中心的運維管理體系建設出發,分享這幾年他親身實踐所總結出來的一些觀點。

嘉賓介紹
智錦
這是真名和全名(編輯注:雖然智這個姓氏比較少)。
2006年~2011年,在支付寶負責系統運維工作,是阿里集團和國內第一批從事運維自動化系統體系建設者。
2011年到2014年, 在建設銀行總行負責運維工具和私有云的建設,運用互聯網的經驗和開源軟件做了一些二次開發。
目前創辦杭州云霽科技,致力于把運維自動化經驗和DevOps的思想做成產品。
主題簡介
現在“運維自動化”、“云計算”、“DevOps”很熱,也有很多解釋,但很多人的理解是狹義的甚至錯誤的。本期分享嘉賓 智錦 將分享其在大型互聯網企業和大型傳統行業的工作感受,并從整個數據中心的運維管理體系建設出發 ,分享這幾年他親身實踐所總結出來的一些觀點。
分享實錄
我在支付寶的時期,剛好是支付寶快速發展的時期,業務每年翻4倍,僅僅3年時間,就從100臺機器達到了上萬臺機器,最早的運維自動化是被業務倒逼,被動的發現問題解決問題的過程。這個經歷,大部分業務快速發展的互聯網公司的都會碰到,解決方式也都差不多,前段時間大眾點評運維總結的非常好。
互聯網的運維自動化,我總結為:“自下而上,野蠻生長”,見效快,但很難有資源停下來思考,相當于華山的劍宗。
我去建行之后,有機會系統的讀了老外的ITIL、COBIT等最佳實踐,也看了不少IBM、HP、BMC的運維產品。客觀的說,老外的方法論和最佳實踐很牛逼,雖然說軟件太復雜,落地難,相當于華山的氣宗。
在和從前在互聯網的實踐經驗驗證之后,突然有一天仰望天空的朵朵白云,豁然開朗,從此劍氣雙修,打通任督二脈,運維自動化的功力大進。
以上為開個玩笑。不過我現在關注的重點主要是整個數據中心的運維管理體系建設,下面分享的也是我這幾年實踐的一些觀點。可能離中小型互聯網公司比較遠一點,會顯得務虛一點。
現在“運維自動化”、“云計算”、“devops”很熱,也有很多解釋,但很多人的理解是狹義的甚至錯誤的。 比如,“運維自動化”這個詞已經被人叫爛了,但大部分人理解的運維自動化,其實只能叫“操作自動化”。再比如,puppet 非常熱,很多人覺得puppet是一個自動化工具,其實puppet的本質和精華是一個配置管理工具。
再說云計算。云計算代表了一種互聯網思維的全新技術路線,其核心思想是采用低成本、標準化的開放硬件和開源軟件構建基礎設施,通過自服務和自動化實現基礎設施資源的交付及運維管理,通過分布式系統實現系統處理能力的無限擴展,并借助合適的應用架構彌補基礎軟硬件的不足,滿足高可用方面的要求。但是云計算實施之后,基礎設施規模急劇膨脹,我們可以發現運維的復雜度是不減反增了。
數據中心的運維管理定義
以前我提過一個黑盒運維與白盒運維的觀點。做了很多年的運維,卻有可能不知道運維的定義是什么。先來給數據中心的運維管理下個定義吧!看看什么是運維。

國際分析機構Garnter把數據中心的運維工作總結為“I&O(Infrastructure & Operation)”,也就是基礎設施管理和運行管理這兩個領域。基礎設施服務是上線前,如何“建設基礎設施”。Opertion是上線后,如何管理業務活動。
我是認為自動化是運行維護的一個方面。 我對于廣義運維自動化的理解,就是體系和閉環的建立。基礎設施層面的閉環是一個運維和運維銜接的小閉環,在運行管理領域,涉及到了運維和開發的大閉環,也就是DevOps。最終的一個現象是,完全的服務化和完全的自動化。
IT運維和IT服務管理的區別,就是一個是被動,一個是主動。
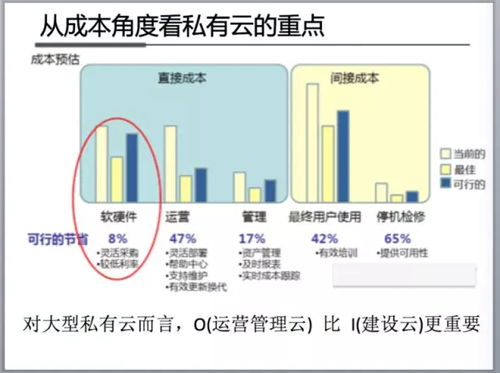
說明:圖大型私有云o和i成本比較 是本期中唯一源自網上的,也是根據garnter報告畫的圖,看了一下大致符合我的認知,就用了,沒有去考證。
上一篇:《火星救援》中你應該知道的5個高可用系統故障恢復原則
下一篇:十個強大的DevOps基礎設施自動化工具,不容錯過(1)
分享到:
 收藏
收藏
收藏
