百度多維度數(shù)據(jù)監(jiān)控采集和聚合計算的運(yùn)維實(shí)踐分享(1)
2016-02-20 19:33:47 來源: 顏志杰 StuQ 評論:0 點(diǎn)擊:
我是百度運(yùn)維部平臺研發(fā)工程師顏志杰,畢業(yè)后一直在百度做運(yùn)維平臺開發(fā),先后折騰過任務(wù)調(diào)度(CT)、名字服務(wù)(BNS)、監(jiān)控(采集&計算);今天很高興和大家一起分享下自己做“監(jiān)控”過程中的一些感想和教訓(xùn)。
公式計算也如此,盡早的過濾不需要的數(shù)據(jù),我們支持四則,邏輯運(yùn)算,當(dāng)agent端具備這樣的表達(dá)能力后,擴(kuò)大了agent采集的能力,可以采集很多有意思的監(jiān)控項:
比如根據(jù)nginx的響應(yīng)時間${cost}和http錯誤碼${errno},去定義損失pv,通過公式:${cost} > 2000 || ${errno} != 200 時間大于2s或errno不等于200,保證聚合計算功能純碎性,降低數(shù)據(jù)傳輸量。
第二個問題,日志如何規(guī)整化,通過命名正則來格式化文本日志,我們用c++寫的客戶端性能較logstash快不少,這里強(qiáng)調(diào)一下,我們沒有像logstash一樣可以支持多個線程去做正則,只有一個線程來計算,這樣做的考慮是:
正則匹配成功性能還可以,一般性能耗在不匹配的日志,出現(xiàn)不匹配的時候,正則會進(jìn)行一些回溯算法之類的耗時操作,agent設(shè)計盡量少進(jìn)入處理“不匹配日志”。
通過增加“前置匹配”功能,類似大家去grep日志的時候,“grep時間戳|grep–P ‘正則’ ”,字符串查找和正則匹配性能相差極大,agent端借鑒這個思想,通過指定字符串查找過濾,保證后面的日志基本都匹配成功,盡量避免進(jìn)入“正則回溯”等耗時操作,在正確的地方解決問題。
這種設(shè)計保證agent最多占一個cpu。實(shí)踐證明,通過“前置匹配”,保證進(jìn)入正則日志基本匹配成功,幾千qps毫無壓力,而且一般只占一個cpu核30%下。
第三個問題,Tag擴(kuò)展性,tag是整個多維度監(jiān)控的精髓,首先我們支持用戶自定義任何tag屬性,有統(tǒng)一的接口提供,你可以對監(jiān)控數(shù)據(jù)上定義任何的tag,比如搜索服務(wù)里面可以加上庫層屬性。
前面提到的運(yùn)營商、省份,這個通過在agent端用一個ip庫來實(shí)現(xiàn)反解,當(dāng)然ip庫更新是一個問題,目前隨著agent的升級來進(jìn)行更新,時效性不高。大家可以考下為何不放在server端處理:)
日志采集agent通過上面的一些手段,基本滿足了在關(guān)鍵指標(biāo)的采集上的要求,完成了“標(biāo)準(zhǔn)化”,數(shù)據(jù)“精簡化”的需求。
總結(jié)一下,日志采集就是標(biāo)準(zhǔn)化的過程,通過采集配置將日志里面的信息變成多維度的數(shù)據(jù)模型,發(fā)送給后端模塊處理。
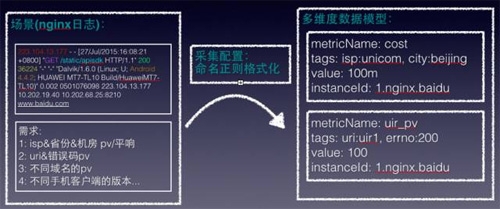
跟logstash比,想強(qiáng)調(diào)前置匹配功能點(diǎn),沒有借鑒其多線程處理的設(shè)計,堅持單線程處理,如果監(jiān)控需要消耗太多的資源去達(dá)到,那么我就對這個合理性存疑了。
采集就介紹到這,下面開始介紹實(shí)時匯聚計算。
前面提到,多維度數(shù)據(jù)監(jiān)控不關(guān)注“單機(jī)”數(shù)據(jù),只關(guān)注聚合數(shù)據(jù),那首先第一個問題,怎么圈定“聚合"范圍?這塊功能在名字服務(wù)中實(shí)現(xiàn),名字服務(wù)不展開。

如上圖,通過名字服務(wù)完成聚合范圍的圈定,支持三級范圍圈定(實(shí)例id=>服務(wù)=>服務(wù)組),一個機(jī)器上的模塊稱為實(shí)例,實(shí)例發(fā)送的數(shù)據(jù)就是剛剛上面講的采集agent發(fā)出來的,每個數(shù)據(jù)都帶一個id標(biāo)示,稱為實(shí)例id。
范圍圈定后,通過指定聚合規(guī)則,我們拼成一個聚合所需要的數(shù)據(jù)結(jié)構(gòu),這個數(shù)據(jù)是自包含的,即監(jiān)控數(shù)據(jù)+聚合規(guī)則都包括在里面,如下圖所示:
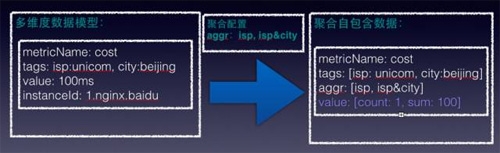
將多維度數(shù)據(jù)+聚合配置變成聚合自包含數(shù)據(jù),自包含數(shù)據(jù)包含了怎么對這個數(shù)據(jù)進(jìn)行計算,上面標(biāo)示要按照isp運(yùn)營商匯聚,以及按照運(yùn)營商和城市來匯聚。
有了聚合自包含數(shù)據(jù)后,就開始進(jìn)行匯聚計算,如下圖所示:
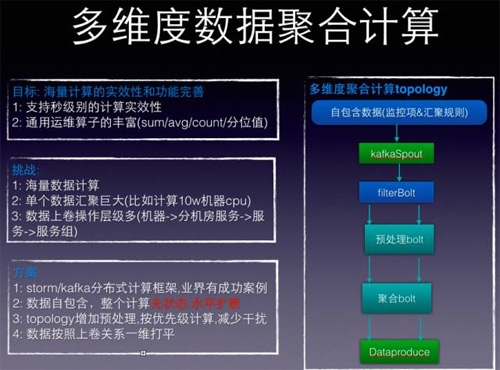
首先我們只支持一些特定的運(yùn)維算子,計算count、sum、avg、分位值、min/max基本上能涵蓋運(yùn)維的需求,比如count就是pv,sum/avg/分位值算平響等。
遇到的挑戰(zhàn)包括:
1.單個匯聚的數(shù)據(jù)量過大,比如要計算10w機(jī)器的cpu_idle,最終需要要按照filed去累加,過大數(shù)據(jù)緩存累加,容易OOM,這個需要考慮storm的算子設(shè)計。
2.數(shù)據(jù)范圍的圈定是支持三層,也就是數(shù)據(jù)上卷操作如何來支持。
先來看第一個問題,介紹storm算子的設(shè)計,大家看下圖:
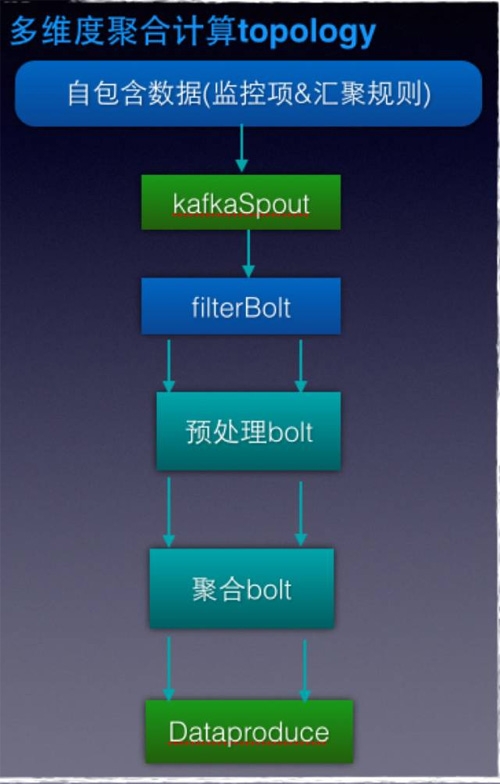
整個topology做到了無狀態(tài),處理的數(shù)據(jù)是自包含,其次計算加了一層預(yù)處理bolt,先用shuffer來處理一層,降低field到聚合bolt的計算量。比如計算10w機(jī)器的10s 鐘cpu_idle(1wqps)先用10個預(yù)處理bolt,每個bolt就是只要累加1/10的數(shù)據(jù),然后到下一層的計算量就會較小了。
相關(guān)熱詞搜索:數(shù)據(jù)監(jiān)控 運(yùn)維 百度
分享到:
 收藏
收藏
收藏
頻道總排行
- Cisco NetFlow v9為何無人問津?
- 技術(shù)專題:智能化運(yùn)維
- 開源代碼管理:如何安全地使用開源庫?
- Facebook架構(gòu)解讀
- IT運(yùn)維分析與海量日志搜索需要注意什么(1)
- 金山運(yùn)維肖力:如何將業(yè)務(wù)遷移到虛擬化環(huán)境并穩(wěn)定運(yùn)行(1)
- Apache Ignite(四):基于Ignite的分布式ID生成器
- CrazyEye,一款國人開源的堡壘機(jī)軟件(1)
- SDN時代的網(wǎng)絡(luò)管理系統(tǒng)會走向何方
- WOT2016吳兆松:Zabbix監(jiān)控自動化的未來如何發(fā)展
頻道本月排行
- 8你消費(fèi)我買單——"漏洞"天使OneRASP...
- 7有了Jenkins,為什么還需要一個獨(dú)立...
- 6IT運(yùn)維分析與海量日志搜索需要注意什么(1)
- 5新浪微博王傳鵬:微博推薦架構(gòu)的演進(jìn)(1)
- 4史上最大機(jī)器學(xué)習(xí)數(shù)據(jù)集,雅虎對外開...
- 4雅虎開源可以提升流操作速度的DataSketches
- 4大眾點(diǎn)評高可用性系統(tǒng)運(yùn)維經(jīng)驗(yàn)分享
- 4云運(yùn)維如何選擇部署適合自身的IDC和...
- 4開源還是商用?十大云運(yùn)維監(jiān)控工具測...
- 4論開發(fā)與運(yùn)維沖突的根源、表現(xiàn)形式及...
