百度多維度數據監控采集和聚合計算的運維實踐分享(1)
2016-02-20 19:33:47 來源: 顏志杰 StuQ 評論:0 點擊:
我是百度運維部平臺研發工程師顏志杰,畢業后一直在百度做運維平臺開發,先后折騰過任務調度(CT)、名字服務(BNS)、監控(采集&計算);今天很高興和大家一起分享下自己做“監控”過程中的一些感想和教訓。

大家好,我是百度運維部平臺研發工程師顏志杰,畢業后一直在百度做運維平臺開發,先后折騰過任務調度(CT)、名字服務(BNS)、監控(采集&計算);今天很高興和大家一起分享下自己做“監控”過程中的一些感想和教訓。
現在開始本次分享,本次分享的主題是《多維度數據監控采集&計算》,提綱如下,分為3個部分:
1.監控目標和挑戰
2.多維度數據監控
2.1.采集的設計和挑戰
2.2.聚合計算的設計和挑戰
2.3.高可用性保障設計
3.總結&展望
首先進入第一部分 :監控目標和挑戰,先拋出問題,裝裝門面,拔高下分享的檔次(個人理解,歡迎challenge)。
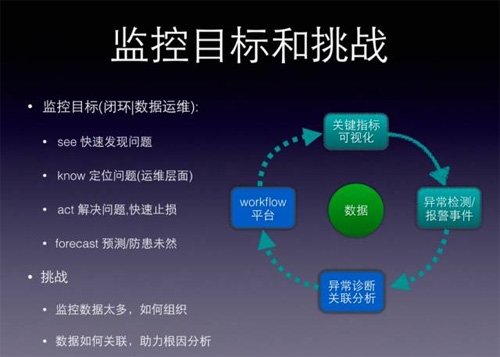
監控期望做到:快速發現問題,定位問題(運維層面),解決問題,甚至要先于問題發生之前,預測/防患未然,形成處理閉環,減少人工決策干預。
先解釋一下“定位問題(優先運維層面)”,意思是站在運維角度“定義故障”,不需要定位到代碼級別的異常,只需定位到哪種運維操作可以恢復故障即可,比如確定是變更引起的,則上線回滾,機房故障則切換流量等…
不是說監控不要定位到代碼級別的問題,事情有輕重緩急,止損是第一位,達到這個目標后,我們可以再往深去做。
再解釋下“預測/防患未然”,很多人第一反應是大數據挖掘,其實有不少點可以做,比如將變更分級發布和監控聯動起來,分級發布后,關鍵指標按照“分級”的維度來展示。(記住“分級”維度,先賣個關子:)
“監控目標”這個話題太大,挑戰多多。收斂一下,談一下我們在做監控時,遇到的一些問題,挑兩個大頭,相信其他在大公司做監控的同學也有同感:
1.監控指標多,報警多
2.報警多而且有關聯,如何從很多異常中找出“根因”
今天先拋出來兩個頭疼的問題,下面開始進入正題“多維度數據監控”,大家可以帶著這兩個問題聽,看方案是否可以“緩解”這兩個問題。
進入正題:
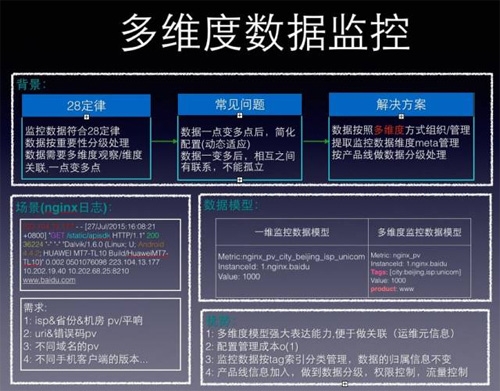
先看第一個問題:監控數據多。監控數據符合28定律,“關鍵”和“次要”指標需要區別對待,不能以處理了多大數據量引以為傲,需要按重要性分級處理,將資源傾斜到重要數據上分析和處理。
分享到:
 收藏
收藏
收藏
