百度多維度數據監控采集和聚合計算的運維實踐分享(1)
2016-02-20 19:33:47 來源: 顏志杰 StuQ 評論:0 點擊:
我是百度運維部平臺研發工程師顏志杰,畢業后一直在百度做運維平臺開發,先后折騰過任務調度(CT)、名字服務(BNS)、監控(采集&計算);今天很高興和大家一起分享下自己做“監控”過程中的一些感想和教訓。
算子可以這么設計是因為計算avg不受影響,avg=sum/count,把10s sum加起來,和先加2s的sum,然后2s中間結果再加起來,除以count,精度沒有損失,但分位值有精度損失,這個需要權衡。
storm算子設計就介紹到這,下面開始介紹數據上卷操作。
數據上卷在接入層做數據一維打平,在接入層的時候按照名字服務的圈定范圍變成了多份自包含數據,比如實例1=>服務2=>服務組3,那么來自實例1的數據就變成兩條數據。
這兩條數據一個范圍屬于服務2,一個屬于范圍服務組3,其他都一樣,也就是犧牲了計算資源,保證整個計算數據都是不相關的,這個其實是有優化空間的,大家可以自己考慮。
到這里多維度采集&計算基本功能點介紹完了。下面就介紹下穩定性的考慮了。
此處有圖:
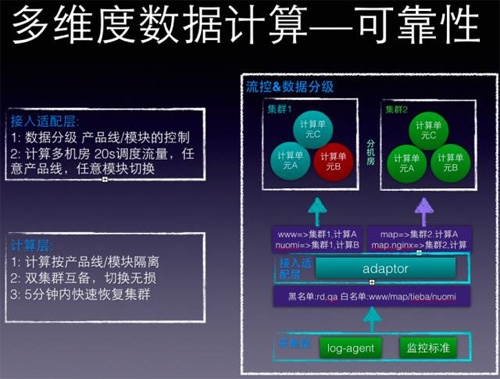
前面一直強調數據符合28定律,所以這個系統首先要支持流控,支持按數據重要性做優先級處理,有如下措施:
第一,接入adaptor層,實現按產品線作為流控基本單元,和使用統計,誰用的多就必須多出銀子,通過設置黑白名單,當出現緊急情況下,降級處理。
第二,聚合計算做成整個無狀態,可水平擴展,多機房互備,因為kafka+storm不敢說是專家,所以在應用架構上做了些文章,主要為:
數據按照名字服務的范圍圈出來后,我們發現,只要保證圈出來的“同一范圍”的數據保證在同一個計算單元計算,就沒有任何問題。
比如建立兩個機房集群1,2,每個機房建立3個kafka topic/ storm計算單元,取名為A,B,C計算單元,通過adaptor,將接收的數據做映射,可以有如下映射:
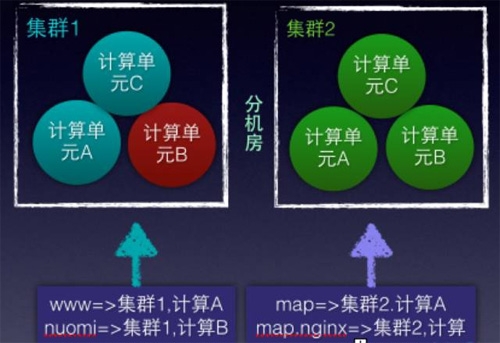
比如地圖產品線的接入服務,命名為:map.nginx,只要范圍map.nginx的數據映射到一個計算單元即可,可以用如下規則:map.nginx接入 => 集群2,1計算單元A
這樣所有map的接入nginx數據就直接將數據寫入到集群2機房的A計算單元來完成,集群2的計算單元B掛了,當然不會影響map.nginx。
總結來說,整個計算都是無狀態,可水平擴展;支持流控,當有異常時,可以進行雙機房切換,如果有資源100%冗余,如果沒有,就選擇block一些產品線,服務降級。
到這里,整個多維度監控采集和計算介紹完成了:)下面說一下總結和展望吧!

采集就是一個標準化的過程,文本用命名正則其實是無奈之舉,期望是pb日志,這樣不會因為日志變動導致正則失效,而且性能也會提升;APM也是一樣,這個類似于lib的功能,不用通過日志能采到核心數據。
個人很看好pb日志,如果能夠有一個通用的pb模板,有一個pb日志的規范推得好,那么還是很有市場的,以后只要這么打日志,用這個模板的解析,就能得到很多內部的數據,不用寫正則。
采集就是一個標準之爭的權衡,估計你不會罵linus大神為啥把進程監控信息用文本放在/proc/pid/stat,而且進程名為啥只有16個字節;標準就在那,自己需要寫agent去將這個標準轉換為你內部的標準。
當你自己推出了監控標準,在公司內部用的很多的時候,RD/op需要努力的去適配你了,他們需要變換數據格式到監控標準上;所以,到底是誰多走一步,這個就需要看大家做監控的能力了:)
聚合計算的考慮則是各種算子的豐富,比如uv,還有就是二次計算,就是在storm計算的數據之上,再做一次計算;比如服務=>服務組的上卷操作可以通過二次計算來完成。
比如服務組包含了服務1、服務2,那么我們可以先只計算服務1、服務2的pv數據,然后通過二次計算,算出整個服務組的pv數據 ,由于二次計算沒有大數據壓力,可以做的支持更多的算子,靈活性,這個就不展開了。
我總結一下:
1.28定律,監控需要傾斜資源處理“關鍵”指標數據。
2.關鍵指標數據需要多維度觀察,1點變多點,這些數據是相互關聯,需要進行meta和配置管理。
3.系統設計時,數據模型先行,功能化、服務化、層次化、無狀態化。
4.對開源系統的態度,需要做適配,盡可能屏蔽開源細節,除了啃源碼之外,在整個應用架構上做文章,保證高可用性。
答疑環節
1.抓取數據的時候需要客戶端裝agent?必須要agent嗎?
從兩方面回答這個問題吧!首先系統設計的是層級化的,你可以不用agent,直接推送到我們的計算接入層;其次,如果你的數據需要采集,那么就是一個標準化的適配過程,比如你的監控數據以http端口暴露出來,那么也需要另一個人去這個http端口來取,手段不重要,重要的是你們兩個數據的轉換過程,所以不要糾結有沒有agent,這個事情誰做都需要做。
2.采集之后,日志是怎么處理的?
日志采集后,通過命名正則進行格式化,變成k:v對,然后將這些k:v對作為類似參數,直接填寫到多維度數據模型里面,然后發給聚合計算模塊處理。相當于對日志里面相同的字段進行統計,上面說的比如地圖nginx日志的處理就是這樣。
3.elesticsearch+logstash百度有木有在用呢?還有kafka在百度運維平臺中的使用是什么狀態呢?
ELK在小產品線有使用,這個多維度監控可以大部分的情況下替換ELK,而且說的自信點,我們重寫的agent性能快logstash十倍,而且符合我們的配置下發體系,整個運維元數據定義等;kafka在剛剛的系統里面就是和storm配合作為聚合計算的實現架構。
但我想強調的是,盡量屏蔽開源細節,在kafka+storm上面我們踩過不少坑。通過上面介紹的這種應用框架,可以保證很高的可靠性。
4.多維度數據監控在哪些場景會用的到,可以詳細說下幾個案例嗎?
我今天講的是多維度數據監控的采集和計算,沒有去講這個應用,但可以透露一下,我們現在的智能監控體系都是在剛剛講的這一套采集&計算架構之上;每層都各司其職,計算完成后,交給展示/分析一個好的數據模型,至于在這個模型上,你可以做根因定位,做同環比監控,這個我就不展開了。
5.能介紹百度監控相關的數量級嗎?
這個就不透露了,但大家也都知道BAT三家的機器規模了,而且在百度運維平臺開發部門,我們的平臺是針對百度所有產品線;所以,有志于做大規模數據分析處理的同學,你肯定不會失望(又是一個硬廣:)
6.不同產品線的聚合計算規則是怎么管理的。不同聚合規則就對應這不同的bolt甚至topology,怎么在storm開發中協調這個問題?
看到一個比較好的問題,首先我們設計的時候,是通用聚合計算,就計算sum/count/avg/min/max分位值,常見的運維都可以涵蓋;我們通過agent做了公式計算,表達能力也足夠了,同時有二次計算。不一定非要在storm層解決。
我提倡“正確的位置解決問題”,當然大家對這個正確位置理解不同。
7.topology無狀態這句話沒太明白。storm topology的狀態管理不是自身nimbus控制的嗎?百度的應用架構在此做了哪些工作或者設計?
我說的是寫的storm算子是無狀態的,整個數據都是自包含的,我們在應用架構上,就是控制發給stormtopology的數據;多機房互備等;我說的應用架構師在這個storm之上的架構。相當于我認為整個storm topology是我接入adaptor層的調度單元。
【編輯推薦】
【責任編輯:火鳳凰 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
